

Is Google still the leader in AI?
Is Google still the leader in AI?
A comparison of Google's latest AI models against the state-of-the-art models from OpenAI and other researchers.

Hi Readers,
Ever since Google shared its latest AI research update a few weeks ago, a question has been on my mind that no one has answered yet:
How do Google’s latest AI models stack up against the competition?
In this post, I will try to answer that question by reviewing Google’s most recent AI advancements across language models, generative images, video, and music and stack them up against state-of-the-art AI models already in the market.
Before I continue, don’t forget to subscribe if you are builders, founder or product manager new to AI and want to receive regular educational content and updates on the space.
Let’s dive right in and find out how Google’s most recent AI models stack up against the state-of-the-art in AI:
First, I’ll pit Google’s latest language model against ChatGPT to see which one has more common sense.
Then I’ll do a four-way test to see if Stable Diffusion, MidJourney and Dall-E can be out-imagined by Google’s latest text-to-image generation model.
Finally I’ll see how Google’s recent advances in video and music generation stack up against the latest models from the AI research community.
1. Large-Scale Language Models
With Microsoft's recent investment in OpenAI and their plan to incorporate OpenAI's GPT model into their products, I thought it made sense to start by focusing on Google’s progress in large-scale language models1 or LLMs.
In April of last year, Google shared its work on a new, large-scale language model called PaLM2. PaLM is a 540 billion parameters3 language model, over three times larger than OpenAI's GPT-34, and was built using a new infrastructure software layer Google also created called Pathways5. It seems that Google's big bet in language models is to go big or go home, which makes sense, given their decades of experience in managing and orchestrating big data. But, is this bet paying off?
Google claims that PaLM's size led to it performing better than state-of-the-art models such as Open AI’s GPT-3 and Google’s LaMBDA6, as described in their April 2022 blog post about PaLM:
We evaluated PaLM on 29 widely-used English natural language processing (NLP) tasks. PaLM 540B surpassed few-shot performance of prior large models, such as GLaM, GPT-3, Megatron-Turing NLG, Gopher, Chinchilla, and LaMDA, on 28 of 29 of tasks that span question-answering tasks (open-domain closed-book variant), cloze and sentence-completion tasks, Winograd-style tasks, in-context reading comprehension tasks, common-sense reasoning tasks, SuperGLUE tasks, and natural language inference tasks.
Google also shared more detailed benchmarking results of PaLM versus state-of-the-art (SOTA) models like GTP-3 below:

Google also claims that PaLM is much better at common-sense reasoning tasks like multiple steps of arithmetic, which they call “chain-of-thought prompting”7:

Google again claims that PaLM outperformed GPT-3 at this type of reasoning and achieved an accuracy approaching that of a 9 to 12-year-old:
We observed strong performance from PaLM 540B combined with chain-of-thought prompting on three arithmetic datasets and two commonsense reasoning datasets. For example, with 8-shot prompting, PaLM solves 58% of the problems in GSM8K, a benchmark of thousands of challenging grade school level math questions, outperforming the prior top score of 55% achieved by fine-tuning the GPT-3 175B model with a training set of 7500 problems and combining it with an external calculator and verifier.
This new score is especially interesting, as it approaches the 60% average of problems solved by 9-12 year olds, who are the target audience for the question set. We suspect that separate encoding of digits in the PaLM vocabulary helps enable these performance improvements.
These claims in Google’s research updates match the sentiment of former Google employees who have interacted with internal previews of Google’s state-of-the-art AI Chatbot LaMDA. They believe it to be a credible threat to ChatGPT. But without public access to PaLM, we are left to take Google’s word for it when it comes to their model outperforming GTP-3… Or are we? 🤔
Which AI model has more common sense: PaLM or ChatGPT?
Google has shared many examples of prompts and response pairs in their PaLM research blog posts, so I decided to try their examples on ChatGPT and make a side-by-side comparison of how PaLM performs versus ChatGPT, which is based on GTP-3.5. It’s worth noting that GPT-3.5 has the same number of parameters as GPT-3 but is trained to be better at following instructions using a process called reinforcement learning from human feedback (RLHF)8.
Example 1 - Counterfactual Reasoning
The first example is a test of how well each model can reason about an outcome given a known fact:

In this example, we can see that even PaLM (left) provides a more direct answer, but ChatGPT(right) can reason about each option. This might reflect ChatGPT being a version of GTP-3 that has been fine-tuned with human feedback, with this response being preferred by the human testers. When I asked ChatGPT to choose one option, it picked option 3, which is correct!
Winner = PaLM slightly beats ChatGPT for getting straight to the answer
Example 2 - Cause and Effect
Next is a simple cause-and-effect example to see how each model understands how one event affects another:
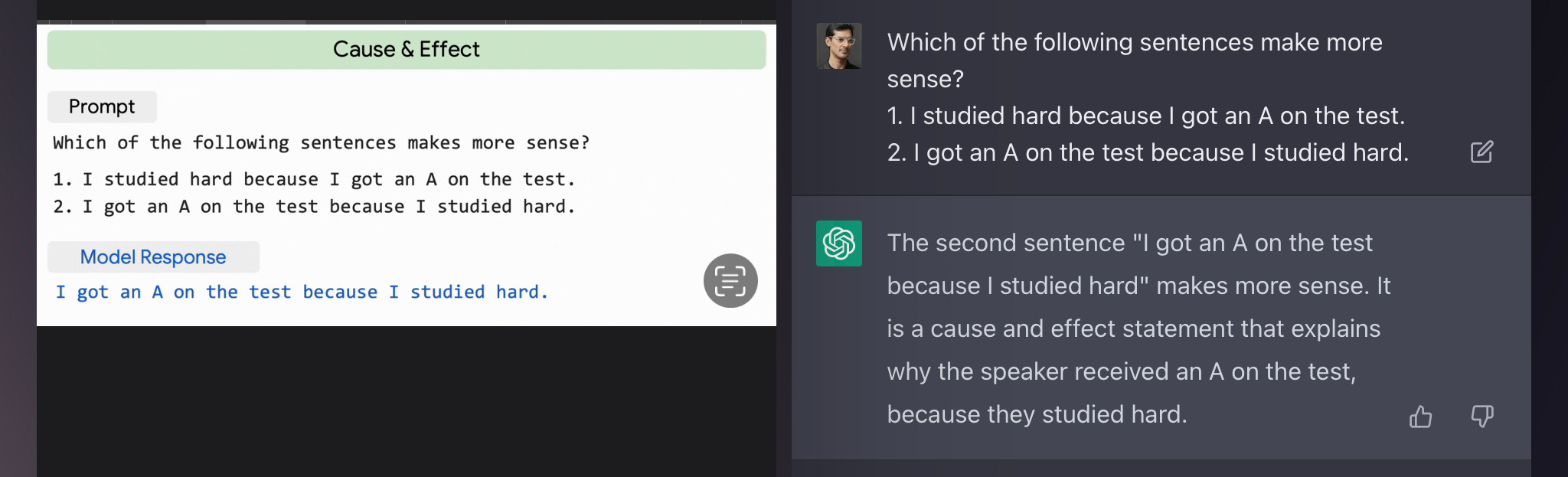
Here we can see that both PaLM (left) and ChatGPT (right) perform fairly equally, with ChatGPT providing a bit more explanation about why it picked option (2).
Winner = ChatGPT beats PaLM for providing a better explanation.
Example 3 - Emoji guessing game
Now, let’s try this fun example Google included where each model has to guess the movie based on some emoji clues!

We can see that ChatGPT(right) performed just as well as PaLM (left) in deciphering the answer, with ChatGPT providing a more helpful explanation.
Winner = ChatGPT again for providing a better explanation
Example 4 - Chain of thought prompting
Finally, in this example, we are testing chain-of-though prompting, to see how well each model can solve a multi-step arithmetic question:

Surprisingly ChatGPT performed just as well as PaLM in this example, even though there was a lot of early criticism that ChatGPT was bad at math9!
Winner = It’s a draw!
Does Google have the upper hand in Language Models?
Based on these four examples I’m not convinced that Google's language models will outperform OpenAI's. In fact, I would say the opposite is true and ChatGPT’s answers are more helpful, which I presume is because they used reinforcement learning from human feedback to tune the model’s responses. It seems that with ChatGPT and GPT-3.5, OpenAI was able to build a model with equivalent performance to Google’s PaLM despite having 3X less parameters.
This leads me to conclude that in large-scale language models, Google’s bet on building bigger models with more parameters may not give them the winning advantage they think. Now, it’s possible that Google is applying reinforcement learning to PaLM as we speak and the next version of their model will far outperform ChatGPT, but we also know that OpenAI are going to be releasing GPT-4 any day now, so the race is on. What is clear is that bigger doesn’t necessarily mean better for language models.
2. Generative Images
When it comes to Image generation, researchers have taken a variety of approaches in the last decade, including Generative Adversarial Networks (GANs)10, Diffusion Models11, Pixel Recurrent Neural Networks (PixelRNNs)12 and Image Transformer13 by Google Brain researchers which made use of the aforementioned Transformer model for Image generation. As Jeff Dean points out, these approaches had a limitation:
Until relatively recently, all of these image generation techniques were capable of generating images that are relatively low quality compared to real world images. However, several recent advances have opened the door for much better image generation performance. One is Contrastic Language-Image Pre-training (CLIP), a pre-training approach for jointly training an image encoder and a text decoder to predict [image, text] pairs.
It’s worth noting that CLIP14 was not discovered by Google’s researchers but by OpenAI. Google's research team has been working on two models: Imagen and Parti. Imagen is a Diffusion Model15, similar to OpenAI's DALL-E 216, with 2 billion parameters. In their published findings17, Google's researchers found that the images produced by Imagen were preferable to humans compared to DALL-E 2 and Latent Diffusion Models (e.g. Stable Diffusion18):
With DrawBench, we compare Imagen with recent methods including VQ-GAN+CLIP, Latent Diffusion Models, and DALL-E 2, and find that human raters prefer Imagen over other models in side-by-side comparisons, both in terms of sample quality and image-text alignment.
You can see how Google’s Imagen model performed against Dall-E 2 and Stable Diffusion when rated by humans here:

Based on Google’s findings, Imagen could be a winning model that puts them ahead of the competition in Generative AI. Once again, I decided to do my own side-by-side to see how the Imagen compares to the three most popular models available right now, Dall-E 2, Stable Diffusion, and MidJourney.
Who can imagine better: Imagen, DALL-E 2, Stable Diffusion or MidJourney?
As with the PaLM comparison, I used Google’s published Imagen prompts and outputs and compared them to what I got by entering the same prompts into DALL-E 2, Stable Diffusion, and Midjourney. For DALL-E 2 and Stable Diffusion (v2.1), I used PlaygroundAI as the editor, but for MidJourney, the only option is to use their Discord channel. For each model, I generated 4 images per prompt and picked the best one.
Example 1 - Chocolate Eagle (easy)
Prompt: “A bald eagle made of chocolate powder, mango, and whipped cream.”
Output:




This was a straightforward prompt, yet it’s interesting to see the different interpretations. In a baking competition, Imagen’s output would probably be the winner, but it is missing whipped cream, which Dall-E’s includes. MidJourney’s output on the other hand, looks like a food sculpture but the cream and mango are less convincing. Imagen, Dall-E, and MidJourney’s output are the most photo-realistic, while Stable Diffusion’s output falls in an uncanny valley of being not quite real looking but also not drawn.
Winner = Draw between Imagen for looks and Dall-E for accuracy
Example 2 - Dog looking at a cat (medium)
Prompt: “A dog looking curiously in the mirror, seeing a cat.”
Output:




This prompt has more complexity as we expect to see both a dog and a cat in the image. Imagen and Dall-E achieve this, while Stable Diffusion and MidJourney only show two dogs. The one additional detail that impressed me about Imagen’s output is that the cat is staring back at the dog. Was this a subtle intention of the prompt?
Winner = Imagen
Example 3 - The Pomeranian (hard)
Prompt: “A Pomeranian is sitting on the Kings throne wearing a crown. Two tiger soldiers are standing next to the throne.”




This was the hardest prompt I tried as it had multiple features: two types of animals, a specific environmental setting, and the relative positioning of characters. Imagen’s output clearly outdoes the competition here, with none of the other models able to create the tigers, though MidJourney did have some tiger-like animals!
Winner = Imagen
Does Imagen have the best imagination?
Imagen seems to perform equally or better than Dall-E 2 consistently and is far better than Stable Diffusion and MidJourney in the examples I tried, especially with more complex prompts. This is probably due to the approaches Google used in building the model, including using a generic large language model pre-trained only on text vs CLIP which is pre-trained on image-text pairs. Google found that making this language model bigger was more effective than making the Image Diffusion model bigger. Strategically it makes sense that Google might go in a direction that doesn’t incorporate OpenAI’s CLIP model, but instead take advantage of its ability to build very large language models.
It’s worth noting that Google has also created a yet-to-be-released editor, Imagen Editor that allows users to edit an image using text prompts, based on their earlier work on DreamBooth19. This capability is already available today however with products like PlaygroundAI, which recently added editing capabilities:


3. Generative Video
Google shared that one of it’s next big areas of focus for AI research is Generative Video which is more complex because of the time component, as Jeff Dean shared:
One of the next research challenges we are tackling is to create generative models for video that can produce high resolution, high quality, temporally consistent videos with a high level of controllability. This is a very challenging area because unlike images, where the challenge was to match the desired properties of the image with the generated pixels, with video there is the added dimension of time.
In video generation, Google’s latest models are Imagen Video20 and Phenaki21. Both models are text-to-video, but Imagen Video uses Diffusion Models, whereas Phenaki uses Transformers.
At a high level, Imagen Video works by using T5, a text-to-text Transformer by Google, to embed22 the input prompt say, "A cat floating through space" into numerical data. This numerical data is then used to condition a diffusion model23 to generate a video consistent with the prompt. This process is similar to image diffusion but uses a video diffusion model that Google published in June 2022. The initial output video is more like a storyboard of the final video, with just 16 frames of video at 3 frames per second verses 24 frames per second for a film. Two more models are then used to fill the video with additional frames and increase the overall resolution. The resulting videos are limited to about 5 seconds long:

Phenaki, Google’s second generative video model, uses transformers to compress video to smaller bite-size pieces called “tokens” in machine learning parlance. These tokens could be a scene, a shot, or some action happening in the video, and they are compressed to be a more abstract representation than the raw video, making it easier for a model to process. A bi-directional transformer24 is then used to generate these video tokens based on a text description. The video tokens are then converted back into an actual video. According to Google, the model can generate variable-length videos, which makes it ideal for storytelling:

Google believes that both models can be used in combination to generate high-resolution long-form videos:
It is possible to combine the Imagen Video and Phenaki models to benefit from both the high-resolution individual frames from Imagen and the long-form videos from Phenaki. The most straightforward way to do this is to use Imagen Video to handle super-resolution of short video segments, while relying on the auto-regressive Phenaki model to generate the long-timescale video information.
Text-to-video generation is still in its nascent stages, and Google’s research does seem to be ahead further along than anyone else in the AI field, which makes it difficult to make any side-by-side comparisons. Meta did recently release their text-to-4d model MAV3D25, which you could imagine being used for Pixar-style animated video, but it doesn’t have the same photo realistic quality that Imagen Video or Phenaki do:

A group of researchers from the University of Singapore also recently published Tune-A-Video26, a text-to-video model that, unlike its predecessors, is only trained on one text-video example to learn a particular scenario (e.g. A man surfing a wave) rather than a large-scale dataset of text-video pairs. Once the model is trained on a video of “A man skiing on snow,” it can then produce variations of “a panda” or “an astronaut on the moon”:




Will Google win in Video Generation?
It’s still too early to tell who will be the winner in text-to-video with state-of-the-art models still in development and all published research in very early stages. It’s entirely possible that Google could have more coming down the pipeline in this domain, and it certainly wouldn’t be a surprise if they came out with a more advanced model this year, given they own the largest dataset of videos on the planet, YouTube. To me, video generation seems like Google’s race to lose.
4. Generative Audio / Music
One of the areas I’m personally most excited to see advancements in is generative audio and music. Last week Google made a massive leap with MusicLM27, a text-to-music model that can generate full-length songs, musical instrument sounds and soundscapes based on a story. Check out the video below for many impressive examples of MusicLM in action from Google’s research website:

MusicLM also builds upon AudioLM, a previous research project from Google that can continue generating audio based on some input audio. It builds on this project by adding the ability to generate audio from text input, on melodic input, and expands beyond piano to many different musical styles like drum N bass.
One of the main challenges of developing a generative music model is the lack of high-quality training data for audio and text pairs. For example, think of your average pop song like “Get Lucky” by Daft Punk, where the title doesn’t provide any description of the actual musical content of the song, its melody, or its instruments. Similarly it’s hard to build these datasets because describing a soundscape (e.g. the sounds in a busy train station) is fairly subjective.
MusicLM works in a novel way by using a previously made embedding MuLan28, which can map the similarity of text to music and vice-versa. Using this embedding, MusicLM doesn’t need to be trained on (music, text) pairs and instead can just be trained on music, then use the MuLan embedding for text conditioning.
Before MusicLM, the closest we had come to text-to-music was Riffusion, a project by a couple of AI engineers that could use text-to-image diffusion to generate audio by first converting audio into spectrogram images. Still, the audio quality was much lower than Google’s ML due to the limitations of how much data you can encode in spectrograms.
Since Google published their research less than a week ago however, four(!) more generative music projects have published updates, including another Google one:
Make an Audio by ByteDance AI Lab is an audio Diffusion model that can do both text-to-audio and video-to-audio.
Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models by @RongjieH project page: text-to-audio.github.io paper: text-to-audio.github.io/paper.pdfMake-An-Audio’s ability to create arbitrary sounds versus just music is impressive, though there’s something uncanny about the output, almost like it’s from a decades-old record.
Noise2Music: 30-second music clips from text prompts again using diffusion, this time from an anonymous research team!
Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts project page: noise2music.github.ioDespite Noise2Music’s 30-second limitation, the fidelity of the audio produced is close to that of MusicLM and much better than Make-An-Audio.
Moûsai: Also another diffusion-based text-to-music generator using Long-Context Latent Diffusion29:
Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion abs: arxiv.org/abs/2301.11757 github: github.com/archinetai/aud…Moûsai’s audio accuracy to the original text is impressive though the audio quality is not as high as MusicLM.
SingSong: Another AI music project from Google, which can provide rhythmically and instrumentally complimentary accompanying music for vocals.
SingSong: Generating musical accompaniments from singing abs: arxiv.org/abs/2301.12662 project page: g.co/magenta/singso…It’s easy to imagine how this model in particular, could be applied to a fun consumer app that lets users do acapella and instantly generate a great soundtrack!
Is everyone going to be dancing to Google’s music?
The fact that five advancements were published in music generation in a matter of one week is a sign that we will see a lot of progress in this space over the next few months. I’ll be watching the space closely to see how it evolves, and especially how audio quality improves. MusicLM, with the highest sounding audio quality, is still at about half that of CD quality.
I think Google has no more advantage than any other research team in a text-to-music generation. There will be many models for anyone building products in the generative music space. I expect Google to focus on providing generative music in their creator tools for Youtube.
How did Google’s AI models stack up?
The goal of this post was to understand better if Google was really playing catch-up in AI or whether they were ahead of the competition, but just weren’t willing to take the risk to make their AI models available to the public, as OpenAI and others have.
Here’s what I found from the comparisons I did of Google’s latest AI models versus those from OpenAI and other researchers:
Language Models: Google’s latest language model PaLM with 3X more parameters than OpenAI’s GPT3 has equivalent performance in answering common-sense questions compared to ChatGPT. This is because of OpenAI’s approach of using reinforcement learning with human feedback to improve GPT3 for ChatGPT’s conversational use case. This shows that in language models, Google’s approach of bigger isn’t necessarily better.
Image Generation: Google’s Imagen is impressive and beats the competition when it comes to harder prompts with different features, something Dall-E, Stable Diffusion, and Midjourney really struggled with. In this case, Google leaning on it’s large language models to encode text descriptions rather than using OpenAI’s CLIP encoding puts it at an advantage. OpenAI may be able to catch up here, but it will be much harder for Stable Diffusion and Midjourney.
Video Generation: Google’s Imagen Video and Phenaki are at the bleeding edge regarding text-to-video generation but we’re still very early in this field. Owning Youtube’s corpus of billions of videos however, makes video generation Google’s race to lose.
Music Generation: Google’s MusicLM and SingSong are promising advances in text-to-music, but with other researchers also publishing comparable models in the last few weeks it’s still anyone’s dance floor!
When comparing Google’s latest research against state-of-the-art models, I was surprised that Google didn’t have the edge I expected. For a company that has been AI-first for many years now and has undoubtedly invested the most in advancing AI research and acquiring AI talent this comes as a surprise. Now, it’s still possible Google has much more impressive models up its sleeve beyond what they have published in research and blogged about. For language models in particular, I have to believe this is the case given the threat of OpenAI and Microsoft’s new partnership.
For Google to truly show its leadership in AI again, they need to take more risks and bring products to market that truly showcase the progress they’ve made in the field. There’s no shortage of excitement about AI right now, but by May when Google plans to announce its new products, it may already be too late to capture the attention of early adopters. Given all the resources and investments Google have put into AI over the last decade, it would be a massive loss for them to come out with products that aren’t at the cutting edge.
On the plus side, for startups entering AI, Google’s lack of dominance is a promising sign that there is still lots of opportunity to compete against the tech giant. The race therefore, has only just begun!
Did you enjoy reading this update from The Hitchhiker’s Guide to AI? If you did, please let me know by subscribing to this free newsletter!
Thanks!
~AJ
A large-scale language model (LLM) is a type of deep learning model that is trained on a large dataset of text (e.g. all of the internet). LLMs predict the next sequence of text as output based on the text that they are given as input. They are used for a wide variety of tasks, such as language translation, text summarization, and generating conversational text. Learn more about LLMs in my post on the origins of deep learning part 3.
Google research announcement on PaLM: http://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html
Machine learning models consist of many layers of mathematical calculations that apply weights, also known as parameters, to a numerical representation of the model’s input to predict a desired output accurately. Modern deep-learning neural models have billions of parameters, as you can see in this handy table of state-of-the-art models:

To learn more about how weights work in neural networks, read part 1 of my Deep Dive on Deep Learning.
Open AI’s GPT-3 (General Pre-trained Transformer 3), the language model that powers Chat-GPT, is an example of a generative LLM that uses the Transformer architecture, enabling it to be trained on a massive text dataset of hundreds of gigabytes using 175 Billion parameters (weights assignments).
Pathways is a software architecture created by google to make it possible to train large language models to complete lots of different tasks. You can learn more about Pathways on Google’s research blog: https://arxiv.org/abs/2203.12533
LaMBDA is Google’s much-hyped conversational AI that one of Google’s researchers claimed was sentient last year, only to be fired immediately afterward.
Chain of thought prompting refers to a large language model generating a series of intermediate reasoning steps to get to the correct answer.
Reinforcement learning with human feedback is a type of machine learning where a computer learns how to complete tasks by receiving feedback from a human. The computer starts off with a basic understanding of how to complete the task and then tries different actions to see what works best. The human then provides feedback to the computer, telling it whether its actions are good or bad. The computer uses this feedback to adjust its behavior and get better at completing the task over time. The goal is for the computer to eventually learn how to complete the task independently, with minimal input from the human. This process can be thought of as a form of teaching, where the human is the teacher, and the computer is the student.
Here’s a great article from AssemblyAI on how ChatGPT was trained, if you want to dive in further: How ChatGPT Actaully Works
ChatGPT made an update on January 30th to further improve math capabilities.
A Generative Adversarial Network (GAN) is a type of artificial intelligence algorithm that is used to generate new data that is similar to existing data. It consists of two parts: a generator and a discriminator.
The generator's job is to create new data similar to the existing data. It does this by using a random input and transforming it into a new piece of data.
The discriminator's job is to tell whether the new data generated by the generator is real or fake. It does this by comparing the generated data to the existing data.
The two parts of the GAN compete against each other. The generator tries to create data that is good enough to fool the discriminator into thinking it's real. In contrast, the discriminator tries to identify whether the data is real or fake correctly. Over time, the generator gets better and better at creating data that looks real, and the discriminator gets better at telling the difference between real and fake data.
The result of a GAN is a generator that can create new data that is similar to existing data, which can be used for a variety of purposes, such as generating images, music, or even speech.
Learn more about GANs from Machine Learning Master: What are generative adversarial networks?
The diffusion process in image generation models refers to the gradual refinement of the generated image over many steps. It starts with a random noise image, and each step applies a series of operations to the pixels of the image to change their values. These operations are designed to gradually add details to the image, so that it resembles the desired image more and more.
The process continues until the image reaches a desired level of detail or quality. One important aspect of the diffusion process is the control over the rate of change, which is critical to producing stable and high-quality images. This is achieved by carefully designing the operations and adjusting their parameters to balance the refinement speed with the risk of introducing unwanted distortions or blurriness.
Overall, the diffusion process is an iterative and gradual approach to image generation that allows the model to explore different variations and produce high-quality images that are consistent and coherent.
Learn more about diffusion in this great Fastai course video:
PixelRNN is a type of artificial neural network that is used to generate images by predicting the next pixel in an image. The network takes an image and processes it as a sequence of pixels, with each pixel being predicted based on the information from previous pixels in the sequence. By repeating this process, the PixelRNN can generate new images that look similar to the original image. The key idea behind PixelRNNs is that they can capture patterns in the image and use these patterns to generate new images that look coherent and meaningful.
Here’s a deeper explainer on PixelRNNs from Towards Data Science: Auto-Regressive Generative Models (PixelRNN, PixelCNN++)
Parmar, N., Vaswani, A., Uszkoreit, J., Kaiser, L., Shazeer, N., Ku, A., & Tran, D. (2018, July). Image transformer. In International conference on machine learning (pp. 4055-4064). PMLR. - arXiv:1802.05751
CLIP (Contrastive Language-Image Pretraining) is a machine learning model that aims to understand the relationship between text and images. It is trained on large amounts of text and image data, with the goal of being able to understand how words in a text description relate to the objects and scenes in an image.
For example, CLIP can be shown an image of a cat and the text description "A furry animal with sharp claws is sitting on a windowsill". It will then learn to associate the words "furry", "animal", "sharp claws", and "windowsill" with the features and objects in the image of the cat. The hope is that by training on many such examples, CLIP will eventually be able to understand the relationship between text and image well enough to generate new images based on textual descriptions, or vice versa.
Overall, CLIP is an AI model that is designed to help computers better understand the relationship between language and images.
Here’s a deeper explainer on CLIP from Towards Data Science: CLIP: The Most Influential AI Model From OpenAI — And How To Use It
Explain Diffusion models
Explain DALL-E 2
"Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding" https://arxiv.org/abs/2205.11487
Stable Diffusion is a Generative Image diffusion model created by researchers and engineers from Stability AI, CompVis, and LAION. It was released as an open-source alternative that was better than Dall-E and available for anyone to fine-tune and change!
You can learn more about Stable Diffusion here: Stable Diffusion: Best Open Source Version of DALL·E 2
Explain DreamBooth
Link to Imagen Video: https://imagen.research.google/video/
Link to Phenaki research page https://phenaki.research.google
Deep neural networks like Imagen Video are layers of mathematical formulas with sometimes millions or billions of “parameters”. An embedding is simply a way of turning non-numerical data like text, into numerical data represents the “meaning” of the text. T5 or Text-To-Text Transfer Transformer, is a deep learning model created by Google in 2020 used for natural language processing (NLP) tasks like translation.
Conditioning a diffusion model means giving the model extra information to follow as it generates an image. In the case of text-to-image generation, the extra information is a special number representation of the text description, called a text embedding. The text embedding guides the image generation process so that the final image looks like what is described in the text. The diffusion model starts with a random image and then improves it step by step, using the text embedding as a guide. By the end of the process, the model has generated an image that looks like what is described in the text.
A bi-directional transformer model is a type of machine learning model that is designed to process sequences of data, such as sentences or video frames. It's called "bi-directional" because it processes the data from both the beginning and the end of the sequence, taking into account both past and future information. This allows it to capture relationships between elements in the sequence that are not immediately adjacent to each other.
The basic building block of a transformer model is the attention mechanism, which allows the model to focus on different parts of the input sequence at different times. The attention mechanism allows the model to dynamically weight different parts of the input sequence based on their importance for the task at hand.
In a bi-directional transformer model, the attention mechanism is applied in both the forward and backward directions, allowing the model to take into account information from both ends of the sequence. This makes bi-directional transformer models well-suited to tasks that involve understanding relationships between elements in a sequence, such as natural language processing or video analysis.
Link to MAV3d: https://make-a-video3d.github.io
Link to Tune-A-Video: https://tuneavideo.github.io
Link to MusicLM: https://arxiv.org/abs/2301.11325
Huang, Q., Jansen, A., Lee, J., Ganti, R., Li, J. Y., and Ellis, D. P. W. Mulan: A joint embedding of music audio and natural language. In International Society for Music Information Retrieval Conference (ISMIR), 2022. https://arxiv.org/abs/2208.12415
MuLan is a music-text embedding model that can understand both music and text. It has two parts, one for music and one for text, that work together to map the two different types of information into a shared space. The text part is based on a pre-existing language model called BERT that has been trained on lots of text data, and the music part is based on a type of neural network called ResNet-50. MuLan is trained on pairs of music and text, and even if the music and text aren't closely related, the model can still find connections between them. The end result is a model that can connect music to natural language descriptions, which can be useful for tasks like finding music based on a description or labeling music based on what it sounds like.
Long-context latent diffusion is commonly used to generate videos , the model is designed to generate videos by taking into account both short-term and long-term context information. The model uses a latent representation, or a compact internal representation of the video, to capture both short-term and long-term information. The model then iteratively refines the latent representation over time, taking into account the context information, to generate the final video.
Long-context latent diffusion allows the model to generate more coherent and stable videos, compared to models that only consider short-term context information. The long-term context information provides a stronger constraint on the video generation process, helping to ensure that the generated video is consistent and coherent over time.
Fantastic post, loved seeing the comparisons. Idea for a future post: can anyone get access to any of these systems today? If so, how? What's the core use case for each? And what's the cost?