

Deep Dive: Could autonomous AI Agents be the next step towards AGI?
Deep Dive: Could autonomous AI Agents be the next step towards AGI?
A deep dive into autonomous AI agents and what it means for our future

Hi Hitchhikers,
A huge welcome to the 350 new subscribers that hitched a ride with us this week. We’re almost at 3,000 Hitchhikers!
Every so often I like to depart from my usual highlights of the week to go deeper into a development in AI that deserves more attention. This week I’m doing a deep dive into autonomous AI Agents and how they could be the next step toward Artificial General Intelligence or AGI. There have been so many exciting developments in this field, from the autonomous code-healing AI I talked about last week to AI agents coordinating tasks and executing more specialized models. I believe this area of AI will be fertile to explore and has exciting and scary implications for the future of knowledge work and accelerating our path toward AGI, which is why I’m excited to cover it today.
Before I jump in, a quick reminder to please share this newsletter with your AI-curious friends to help me get to 5,000 subscribers by June. We’re more than halfway there already!
What are autonomous AI Agents?
In last week’s post, I talked about how AI is revolutionizing software development, and one example I gave was AutoGPT, a project that uses GPT-4 to self-heal code. In that post1, I wrote:
Anyone who has spent a lot of time debugging code knows that this is a tedious process and can often take much longer than writing the code in the first place. With tools like Auto-GPT and the recently announced Github Copilot X, this is going to be a thing of the past.
This idea of autonomous agents isn’t just limited to code, however, and in the last few weeks, there haven’t been a growing number of attempts to build GPT-powered autonomous agents that can do much more!
My favorite example of this to date is BabyAGI, an agent created by Yohei Nakajima, a Venture Capitalist, that uses GPT-4 and Pinecone2 for memory to create and perform tasks autonomously!


Here's how BabyAGI works:
BabyAGI uses OpenAI and Pinecone APIs to perform its operations. It leverages GPT-4 to create new tasks and Pinecone to store and retrieve task results for context.
The system creates tasks based on the result of previous tasks and a predefined objective e.g. “Read this article and write a summary of it”. The tasks are then prioritized and executed in a specific order.
The script operates in an infinite loop, and in each iteration, it performs the following steps:
It pulls the first task from the task list.
It sends the task to the execution agent, which uses OpenAI's API to complete the task based on the context.
It enriches the result and stores it in Pinecone.
It creates new tasks and reprioritizes the task list based on the objective and the result of the previous task.
The execution agent function sends a prompt to OpenAI's API, which returns the result of the task. The prompt consists of a description of the AI system's task, the objective, and the task itself.
The task creation agent function creates new tasks based on the objective and the result of the previous task. It sends a prompt to OpenAI's API, which returns a list of new tasks as strings.
The prioritization agent function reprioritizes the task list based on the objective and other factors. It sends a prompt to OpenAI's API, which returns the reprioritized task list as a numbered list.
The script uses Pinecone to store and retrieve task results for context. A Pinecone index is created based on a specified table name, and Pinecone is then used to store the results of tasks, along with the task name and any additional metadata.
In summary, BabyAGI is an AI system that autonomously manages tasks by creating, prioritizing, and executing them based on a predefined objective and the outcomes of previous tasks. It interacts with GPT-4 for natural language processing and uses Pinecone for data storage and retrieval.
What I found most impressive is that BabyAGI does all the above in just 180 lines of code3 which Nakajima generated using ChatGPT because he had no coding experience himself!
Here are a few examples of BabyAGI in action:
1/ A founder needs help to win more customers for their SaaS product. BabyAGI starts by creating a task list and then works its way through each task!





2/ Let’s get BabyAGI to make money. It decides to create an online business!


3/ BabyAGI becomes an angel investor:


In all the examples, you can see how BabyAGI starts by breaking down the objective into smaller tasks and then carrying out those tasks while continuing to iterate on the task list. In these cases, you can see that BabyAGI is using GPT’s understanding of the world to complete tasks but imagine if it could expand its capabilities beyond just GPT’s training data to interact with the real world too!
What else can autonomous AI agents do?
AutoGPT and BabyAGI aren’t the only project attempting to build autonomous agents. Microsoft has also been working on a project called JARVIS, named after the fictional AI assistant to Iron Man. Similar to BabyAGI, JARVIS uses OpenAI’s GPT to coordinate tasks, but relies on more specialized HuggingFace models to carry out those tasks:

JARVIS operates as an interactive system where users can enter their requests, and the system responds accordingly, leveraging the capabilities of both the LLM and the expert models. Its ability to use other machine learning models as tools gives it more powerful capabilities not just to plan an objective into many tasks like BabyGPT but also to use additional inputs like image recognition to help it complete tasks too.
Here’s an example of how JARVIS can be used to identify and count Zebras:

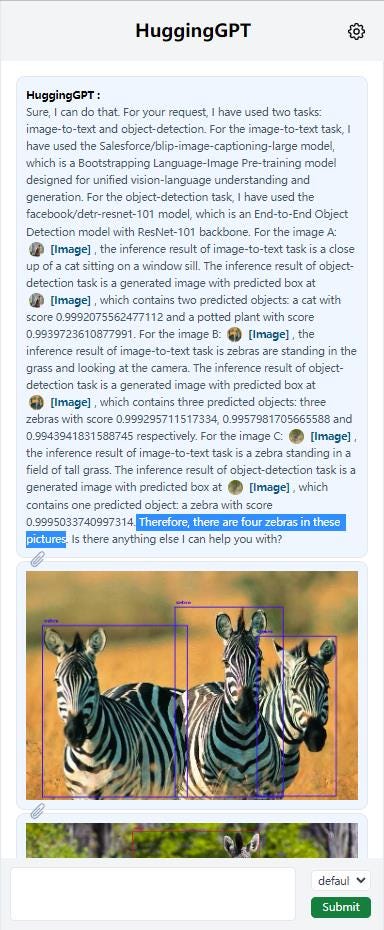
You can see that GPT calls on a more specific image recognition model by Salesforce to caption each image, and then a Facebook model to carry out object detection. It uses both of these to conclude that the photos contain 4 zebras altogether. The effect of combining GPT with these more specific models is that it can now more effectively interact with the real world. In the above example, Microsoft has effectively given GPT eyes!
This paradigm extends beyond object recognition and can be applied to understanding other types of visual content too like Charts and Graphs. Here’s an example from HuggingFace augmenting LLMs with charting and math capabilities.


This can be reversed too, by giving LLMs the ability to create and edit images, for example, using Stable Diffusion as in this example by Pietro Schirano:

In the example, ChatGPT was able to use StableDiffusion to generate images based on Pietro’s instructions. Pietro then took it one step further and asked ChatGPT to draw itself!

It’s not hard to see how these concepts could be combined to create an autonomous agent that can very quickly become useful in the creative field and, more interestingly, starts having its own imagination! 🤯
How do autonomous AI agents relate to AGI?
I believe there is a more profound implication for these types of iterative, LLM-powered autonomous AIs that can use other tools/models to complete tasks. It feels much closer to how humans interact with the world, whereby we have additional sensory input beyond our brain’s intelligence, and we use tools to complete our objectives. Many folks, including myself, have wondered if this paradigm is a promising path toward AGI. In my last podcast with Charlie Newark-French4, we discussed how AGI could manifest as a collection of these autonomous agents we interact with in the world rather than a centralized all-powerful super intelligence.
The most obvious immediate impact such agents might have on our society is in knowledge work, where economic productivity is primarily in the form of interacting with, processing and creating information. Autonomous AIs may soon be able to carry out lower-skilled jobs in professions like law, accounting, consulting, product management, sales, etc., as long as they are supervised by a human.
We’re already starting to see disruption in professional services, with examples like Harvey, an AI copilot for the legal profession:


I expect to see more industry-specific examples like this follow over the next year, but they will go beyond document generation to actual task completion!
What does this mean for our global economy?
There are 1 billion knowledge workers in our global economy today5. I expect within the next 3-5 years, every knowledge worker will have an AI copilot to help them work faster and smarter. Of course, companies that provide these copilots will have the training data to make them better and better with human feedback. It’s not a giant leap to assume then that we will eventually be able to use that feedback along with the autonomous AI approach I’ve discussed in this post to replace parts of the knowledge worker market altogether.
Think about that for a second. Imagine just 20% of knowledge workers could be replaced by autonomous AI. That’s 200,000,000 jobs. What does that mean for our economy? Will we make more things as a result because of higher margins? Or will we automate more and more jobs so we can produce the same amount of goods with far fewer people?
Billions of dollars of wealth will be created, but just as much damage may be done to the livelihoods of people displaced by AI. And it's not only about the economic implications; it's also about the values we want to uphold in a society increasingly influenced by AI. As we move towards a world where AI copilots are the norm, we'll need to consider privacy, consent, and data ownership issues. Who has access to the data generated by AI copilots, and how is it used? How do we ensure that AI systems respect the rights and autonomy of individuals?
At the same time, there’s so much societal upside to this future, too with the opportunity to democratize access to knowledge and skills. In a world where AI copilots can assist with legal work, accounting, and product management, we have the potential to unlock knowledge and expertise for a broader audience.
As AI continues to evolve and redefine our work, we'll need to continually learn and adapt to new tools and paradigms. That’s why I created The Hitchhiker’s Guide to AI. To spread the word about AI and encourage more people to embrace the excitement of exploration and discovery while also staying up to date on the societal implications of this powerful technology. Our adventure into the realm of AGI is just beginning, and it promises to be a fascinating, challenging, and transformative ride.
Thank you for reading this week’s edition of The Hitchhiker’s Guide to AI. If you enjoyed this post and want to hitch a ride with us, please smash that subscribe button!

Pinecone is an example of a vector database, and it provides a cloud-based service that allows users to store, search, and manage vectors efficiently. It's built specifically to handle the challenges of working with large-scale vector data.
A vector database is a type of database that is designed to store and manage high-dimensional vectors. In this context, a vector is a mathematical representation of data, often in the form of a list of numbers. Vectors can represent a wide variety of data, such as images, audio, text, and more. In many cases, these vectors are generated by machine learning models that convert raw data into a fixed-size numerical representation.
Now, let's see why vector databases are useful for knowledge retrieval for large language models (LLMs):
Efficient Similarity Search: Vector databases like Pinecone can quickly find vectors that are similar to a given query vector. This is called similarity search, and it's important for knowledge retrieval because it allows the LLM to find relevant information that is similar in meaning to the input query.
Scalability: As the amount of data grows, it becomes more challenging to manage and search through it. Vector databases are designed to handle large amounts of vector data, making them well-suited for LLMs that deal with extensive knowledge bases.
Semantic Understanding: Vectors can capture the semantic meaning of text or other data. By using vectors to represent knowledge, LLMs can go beyond simple keyword matching and understand the underlying meaning of queries and information.
Flexibility: Vector databases can handle a wide range of data types, not just text. This means that LLMs can use vector databases to integrate and retrieve knowledge from diverse sources, including images, audio, and more.
In summary, vector databases like Pinecone provide a way to store, search, and manage high-dimensional vectors efficiently. This capability is essential for LLMs because it allows them to retrieve semantically relevant knowledge to a given query, even when dealing with vast and diverse datasets.
The author confuses the concepts of "autonomous" and "automatic".
The automatic system performs a certain task, having received it from the user, and then waits for a new task. The autonomous system operates without pause, carrying out its mission, even if no instructions are given.
The systems described by the author are typical automata, not autonomous systems, in terms of how they organize work, differing from a spell checker or script interpreter only in the type of actions performed. An example of an autonomous system is an anti-virus program.