

🤓 A Deep Dive into Deep Learning - Part 1
🤓 A Deep Dive into Deep Learning - Part 1
The first of three posts on the history of Deep Learning and the foundational developments that led to today’s AI innovations.

Deep learning is a field of AI that focuses on using data to teach computers how to perform tasks that traditionally required human intelligence, by mimicking the structures of the human brain. In this three part series, I’m going to provide a history of Deep Learning based on Lessons 1-3 of Fastai’s Practical Deep Learning course and Chapter 1-3 of the accompanying book1. If you want to learn more about Fastai, checkout my previous post.
The field of deep learning is filled with lots of jargon. When you see the 🤓 emoji, that’s where I go a layer deeper into foundational concepts and try to decipher the jargon.
P.S. Don’t forget to hit subscribe if you want to receive more AI content like this!
Part 1 - The dawn of the Neural Network
1940s-1950s
You may be surprised to learn that concept of abstracting the human brain into a computer actually dates back to the 1940s. In the 1940s, a neurophysiologist Warren McCulloch and a logician Walter Pitts develop a mathematical model of an artificial neuron2. This work is then further developed by a psychologist name Frank Rosenblatt, who adds the ability for the artificial neuron to learn. He also builds on the first device that uses the concept of the artificial neuron, called the Mark I Perceptron in 19573. Rosenblatt successfully demonstrates that his artificial neuron can perform binary classification, recognizing simple shapes!

🤓 What is a perceptron?
Neurons are nerve cells in the brain that process and transmit chemical and electrical signals. A perceptron is a simplified representation of a neuron in our brains, that is used in an artificial neural network. It classifies input data into one of two categories e.g. pictures of dogs vs. cats.
Here's how a perceptron works:
The perceptron receives input data in the form of numerical values, called "features.".
The input data is multiplied by a set of weights, which are also numerical values that are used to adjust the importance of each feature.
The weighted input values are then summed together, and the sum is passed through an activation function. The activation function determines whether the perceptron "fires," or activates, based on the input.
If the perceptron activates, it outputs a "1." If it does not activate, it outputs a "0."
How is this output used?
The output of the perceptron is used to classify the input data into one of two categories. For example, if the perceptron outputs a "1," the input data might be classified as belonging to one category like “dogs”. If it outputs a "0," the input data might be classified as belonging to a different category like “cats”.
1960s
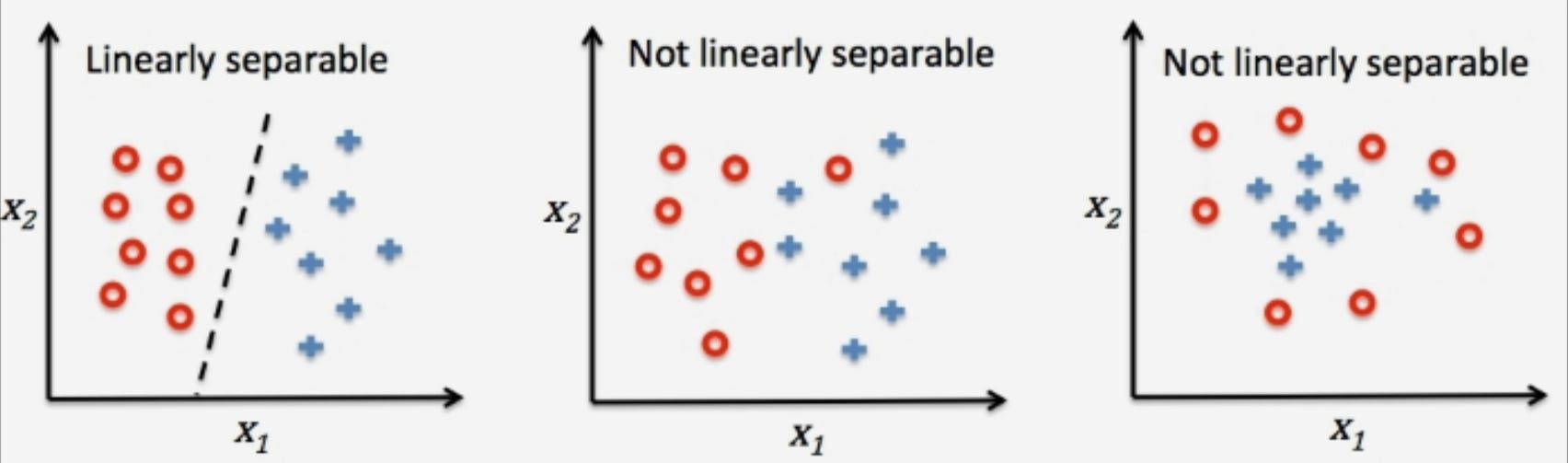
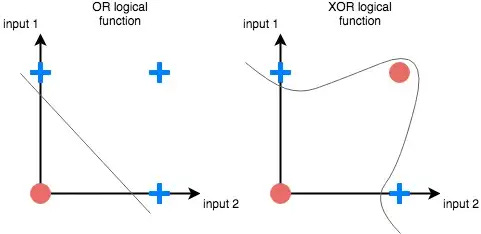
Marvin Minsky, an MIT profressor and Seymour Papert, a mathematician publish a book4 about Rosenblatt’s machine. In the book they show that Rosenblatt’s perceptron was limited in its capabilities as was any other single layer perceptron. Crucially, they prove that it can’t learn the simple logical function XOR5, because XOR is not linearly separable.
🤓 What does it mean to be linearly separable?
Data is linearly separable when the data points within that data can be separated into two classes using a straight line. For example, if we have a dataset of two classes, "dogs" and "cats," and the data points for "dogs" have a feature A = big ears and feature B = long tail, whereas data points for "cats" have feature A = small ears and feature B = short tail, it will be possible to draw a line in a 2D space to separate these two classes with all the "dogs" points on one side of the line and all the "cats" points on the other side.
As we’ll find out soon, the fact that single layer perceptrons can only separate data that is linearly separable end up being a huge limitation to its application.
1960s continued
In 1962 Arthur Samuel, a researcher at IBM publishes an essay “Artificial Intelligence: A Frontier of Automation,”6 in which he defines way to get computers to complete tasks: Machine Learning.
🤓 What is Machine Learning?
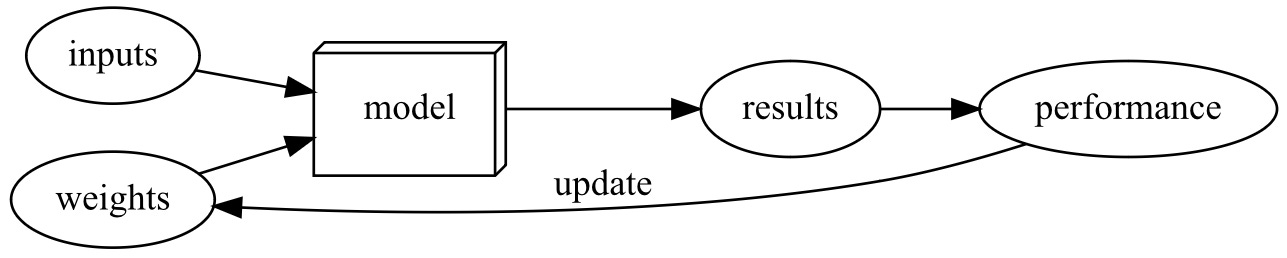
Unlike regular programming, Machine Learning does not take the approach of spelling out each step by step instruction to achieve a certain task. Instead, Machine Learning takes a set of input values and assigns some weights to those inputs that define how the input is processed in order to produce a specific result. This key difference changes the process from a program to a model. A model is a special type of program that can do many different things depending on the weights assigned to it.
But wait, isn’t that just a different type of program, like a recipe for cooking?
Not quite. The other big difference is unlike a recipe where the “weights” of ingredients are constant, in Machine Learning the weights are not constant. In fact, they themselves are variables that can change the way the inputs are processed depending on their assignment.
So how do we set the correct weights to get the best result?
In order to know if the weights are assigned to maximize performance, we need a way to automatically test the effectives of any weight assignment. We can do this by providing input data i.e. pictures of cats and dogs, and seeing if the resulting predictions are accurate or not.
OK, but what if the weight assignments are wrong and the results aren’t very good?
In Machine Learning there’s a mechanism for altering these weights automatically in order to maximize performance of the model to achieve the best results. We call this process training the model.
Putting this altogether, we have process by which we assign weights to a model automatically, and then alter these weights automatically, constantly testing the models result to maximize the performance. This process is what we call Machine Learning.
1970s
Advancements in the field of neural networks almost grind to a halt. Academics aren’t convinced of the usefulness of neural networks because of Minksy and Papert’s findings on the limitations of single layer perceptrons. Unfortunately they don’t recognize another crucial finding that Minksy and Papert also had in the same book: Multiple layers of perceptrons can represent more complex functions and data. The limited computational power of computers at the time also makes it difficult to train larger and more complex neural networks.
🤓 What is a neural network?
A neural network is a type of machine learning model that is inspired by the structure and function of the human brain. It is composed of a large number of interconnected "neurons" (e.g. perceptrons) that are organized into layers. These layers process and pass information through the network in a way that allows it to learn and make predictions or decisions.
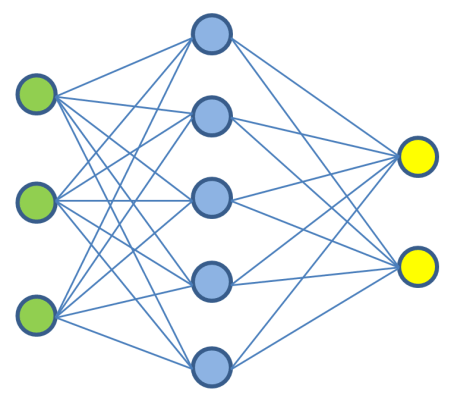
How does it actually work?
At a basic level, a neural network takes in inputs, performs computations on them, and produces outputs. The inputs are usually in the form of numerical values and are passed through the network where they are processed by the interconnected neurons. Each neuron performs simple mathematical computations on the inputs it receives and sends the result to other neurons in the next layer. In this way, the input data is transformed and distilled as it flows through the network, and eventually, an output is produced.
But not all data comes in the form of numerical values, for example pictures?
Data is often preprocessed and transformed into numerical values before it is input into the network. This process is known as feature extraction or feature engineering.
For example, when working with image data, the raw pixel values of the image need to be transformed into numerical values that the neural network can process. One way to do this is by normalizing the pixel values to a specific range, such as between 0 and 1, so that the network can more easily learn from the data. Another way is to extract features from the image, such as edges, corners, or color histograms, which can be represented as numerical values.
What about text data?
When working with text data, the text is typically tokenized and encoded as numerical values. Tokenization involves breaking the text into individual words or phrases, and encoding converts each word or phrase into a numerical value. This is often done using a technique called one-hot encoding, where a unique number is assigned to each unique word or phrase.
How do these neural networks learn things?
A neural network can learn by adjusting the strengths of the connections between the neurons, known as "weights," to minimize the difference between the output produced by the network and the desired output. This process is done through a training process by providing the neural network with labeled data which allows it to learn the mapping between inputs and outputs.
What are these neural networks used for?
Neural networks can be used for a wide range of applications, such as image recognition, natural language processing, speech recognition, and many others. They are particularly useful for tasks that involve large amounts of data and complex patterns, such as image and speech recognition.
1970s continued…
In 1974 Paul Werbos, invents an algorithm that that was ignored for decades but today is an important foundational tool in the field of machine learning and neural networks: Backpropogation7. In his PhD thesis, Werbos described the backpropagation algorithm and demonstrated its ability to train artificial neural networks to perform tasks such as function approximation and time series prediction.
🤓 What is backpropagation?
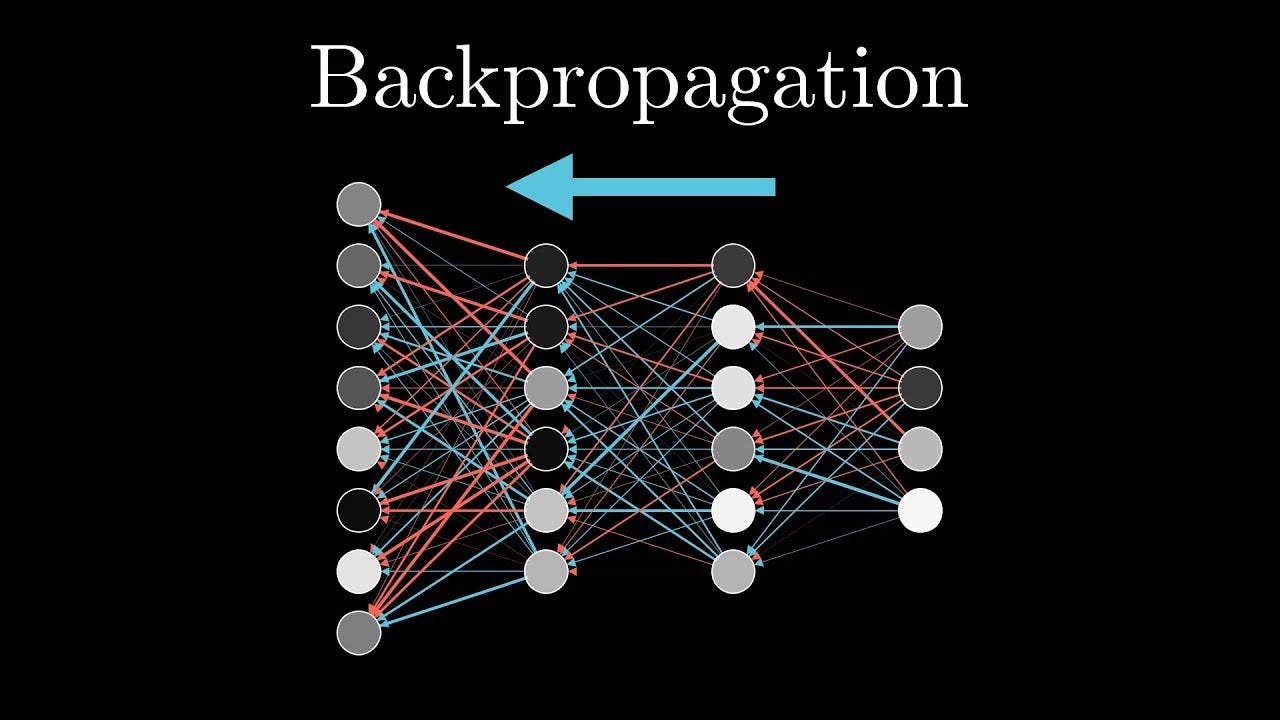
Backpropagation is a training algorithm for artificial neural networks that is used to calculate how accurate a network is at predicting the right output and adjust its weights to make it more accurate e.g. make it better at identifying dog pictures as dogs.
This accuracy is measured using a loss function. An ideal loss function returns a value that is small loss when the model is performing well (e.g. identifies most dog pictures as dogs) and a large loss when the model is performing poorly (e.g. identifies most dog picture as cats)
What’s a good example of a loss function?
One of the most common loss functions used in backpropagation is the mean squared error (MSE) loss function. MSE measures the average squared difference between the predicted output and the true output. The MSE loss function is often used in regression tasks, where the output is a continuous value.
How is a loss function used in backpropagation?
Here's how backpropagation works:
The neural network is presented with an input and makes a prediction. e.g. an image of a
catdog.The prediction is compared to the true output, and the loss is calculated. In this case we know the image is a dog and we compare that to the prediction the model makes on how likely it is to be a dog.
The loss is propagated backwards through the network, and the weights of the network are adjusted to minimize the loss. This is done by using an optimization algorithm, such as gradient descent, which adjusts the weights of the network in a way that reduces the loss.
This process is repeated for many input-output pairs, and the weights of the network are continually adjusted to minimize the loss.
The process is stopped when the loss is below a certain threshold or when the weights of the network have converged to a stable solution, meaning they are no longer changing.
Wait, what is gradient descent?!
Gradient descent is an optimization algorithm used to find the optimal set of weights for a model. Machine learning models often have many weights that need to be set in order for the model to work properly. The goal of training a machine learning model is to find the values for these weights that result in the best performance on the task at hand.
If you want to go deeper into exactly how backpropagation and gradient descent works, checkout this great Youtube video by Andrej Kaparthy (Tesla, Open AI):
To be continued…
We end Part 1 at the close of the 1970s in the AI winter. Research has slowed down because of Minksy and Papert’s findings on the limitation of single layer neural networks and computers aren’t yet powerful enough to train large networks. Meanwhile, although backpropagation has been discovered it is yet to be adopted widely in the field of neural networks.
What will be the fate of neural networks in 1980s?
Continue to Part 2 to find out…

Fun fact: I used ChatGPT for a lot of the research for this series. Over the course of a week I asked ChatGPT dozens of questions about the history of deep learning and the concepts behind it. To make sure the article was accurate, I asked ChatGPT to provide citations to relevant scientific papers which I’ve included in the footnotes. If you find any errors, please reach out or comment below and I will fix them!
If you enjoy reading my posts and would like to receive more content about AI for builders, founders and product managers.
Jeremy Howard, Sylvain Gugger. Deep Learning for Coders with Fastai and PyTorch: AI Applications Without a PhD, O’Reilly Media, Aug. 2020
McCulloch, W. S., A logical calculus of the ideas immanent in nervous activity. The Bulletin of Mathematical Biophysics, 5(4), (1943), 115-133.
Frank Rosenblatt, The Design of an Intelligent Automaton. Research Trends 6, no. 2 (1958), pp. 1-7.
Marvin Minsky and Seymour Papert, 1972 (2nd edition with corrections, first edition 1969) Perceptrons: An Introduction to Computational Geometry, The MIT Press, Cambridge MA, ISBN 0-262-63022-2.
The XOR (exclusive OR) function is a logical operation that takes two inputs and returns a "true" output (1) if exactly one of the inputs is "true" (1) and a "false" output (0) if both inputs are the same.
SAMUEL, ARTHUR L.. "Artificial intelligence – a frontier of automation" it - Information Technology, vol. 4, no. 1-6, 1962, pp. 173-177.
P. Werbos, "Beyond regression: New tools for prediction and analysis in the behavioral sciences," Ph.D. dissertation, Committee on Appl. Math., Harvard Univ., Cambridge, MA, Nov. 1974
This is really good.