

GPT-4's killer use-case, Microsoft and Google's AI battle comes to your workspace, plus LLaMAs for everyone
GPT-4's killer use-case, Microsoft and Google's AI battle comes to your workspace, plus LLaMAs for everyone
The three most important things that happened in AI this week.

Hi Hitchhikers!
A massive welcome to the 750+ subscribers since my last post. We’re now at over 1,700 subscribers, a goal I thought I wouldn’t reach until the fall! Thank you all for supporting this substack. I usually aim to have this weekly highlights newsletter go out on Sunday morning, but this week, I’m running a little late as I had a friend visiting from out of town.
Here are the three most important things that happened in AI last week, that I will be covering in this post:
Why OpenAI’s GPT-4 is a watershed moment for AI.
What Google and Microsoft’s new AI features mean for the Big Tech AI war.
How Stanford’s new large-scale language model Alpaca is the first step towards making AI more universally accessible.
Before we jump in, if you enjoy reading this newsletter please share it with a friend!
1. OpenAI launches GPT-4
In case you missed it, last week OpenAI finally unveiled GPT-4, their latest state-of-the-art large-scale language model1:

They also hosted a live stream demo of GPT-4, which I encourage you to watch if you have 24 minutes spare as the demos really do a good job of showcasing GPT-4’s capabilities:
GPT-4 was made available to developers via OpenAI’s API and to end users who subscribe to ChatGPT Pro. The new model is jam-packed with many new features. Let’s go through the three major ones…
1/ Better understanding and creativity:
One of GPT-4's most significant new features is its ability to understand more complex and nuanced prompts and provide more creative replies. This means you can ask GPT-4 more sophisticated questions or give it more detailed instructions and expect better results. For example, in OpenAI’s own research paper, they showed how GPT-4 can help with drug discovery by identifying new chemical compounds:


Another example of GPT-4’s creativity is by this Twitter user who used it to come up with ideas to start a business using only $100…


And here's a different example of GPT-4 coming up with novel explanations for things we don’t understand in the universe today, like Fermi’s Paradox2:


The common theme seems to be that GPT-4 is better than its predecessor at not just answering questions but also coming up with ways to solve problems creatively, often in a back-and-forth manner with the user.
2/ Multimodal capabilities:
The previous version of ChatGPT was limited to just text prompts. But with GPT-4, OpenAI demonstrated that you can also use images as inputs although this is currently still in early testing. Combining text and images can create richer and more engaging conversations with ChatGPT. This opens up a whole new range of possibilities for using ChatGPT for tasks like image captioning, character recognition, e-commerce recommendations and even dating apps!
OpenAI’s CTO Greg Brokman shared an impressive example of this feature during the live stream. In the demo, he made rough sketch of a website on a napkin and then used GPT-4 to generate the code to build the site, just based on a photo of the napkin!

Here’s another example in their research helps to highlight how image entry can really expand the capabilities of the model when it comes to interpreting what’s in an image:

While image input isn’t generally available yet, OpenAI also announced a partnership with a Danish accessibility startup Be My Eye, to use GPT-4 to help blind people interpret to navigate the world around them.
I’m excited to see more creative use cases for image input once OpenAI releases the feature more broadly!
3/ Longer input token size
GPT-4 will be able to process 25,000 words (roughly 50 pages) of prompt text, which is 4x the size of GPT-3. A longer prompt size enables GPT-4 to process much more complex context from a user, for example, a whole research paper, the complete documentation for an API or the transcript of a two-and-a-half hour-long podcast. This is an important feature because GPT -4's knowledge is still limited to 2021 just like GPT-3. Therefore to use GPT-4 to reason about more recent content or proprietary data not in the original training set, the content has to be included in the prompt. For example, in OpenAI’s demonstration, they showed how the raw text of Discord’s API could be dumped into GPT-4’s prompt to write a bot that interacted with the API.
This feature of combining GPT’s reasoning with external data is a vastly underestimated superpower. With a longer prompt, it’s possible to solve many more novel use cases like the ones mentioned in this post:


OpenAI has currently limited the longer prompt version of their model to their API users, so you can’t test it out on ChatGPT Pro. I expect however that in the coming weeks we’re going to see some more examples of GPT-4 being used with external data to solve some compelling real-world problems.
Does GPT-4 live up to the hype?
There was a lot of hype around GPT-4 include a now infamous Twitter rumor3 that it would have 100X more parameters than GPT-3, matching the complexity of the human brain.
So does GPT-4 live up to the hype?
OpenAI declined to share details about the size of the model, citing competitive reasons. However, in OpenAI’s own research paper, they did share multiple benchmarks which objectively show that GPT-4 is much smarter than GPT-3, for example, when it comes to pass standardized tests:
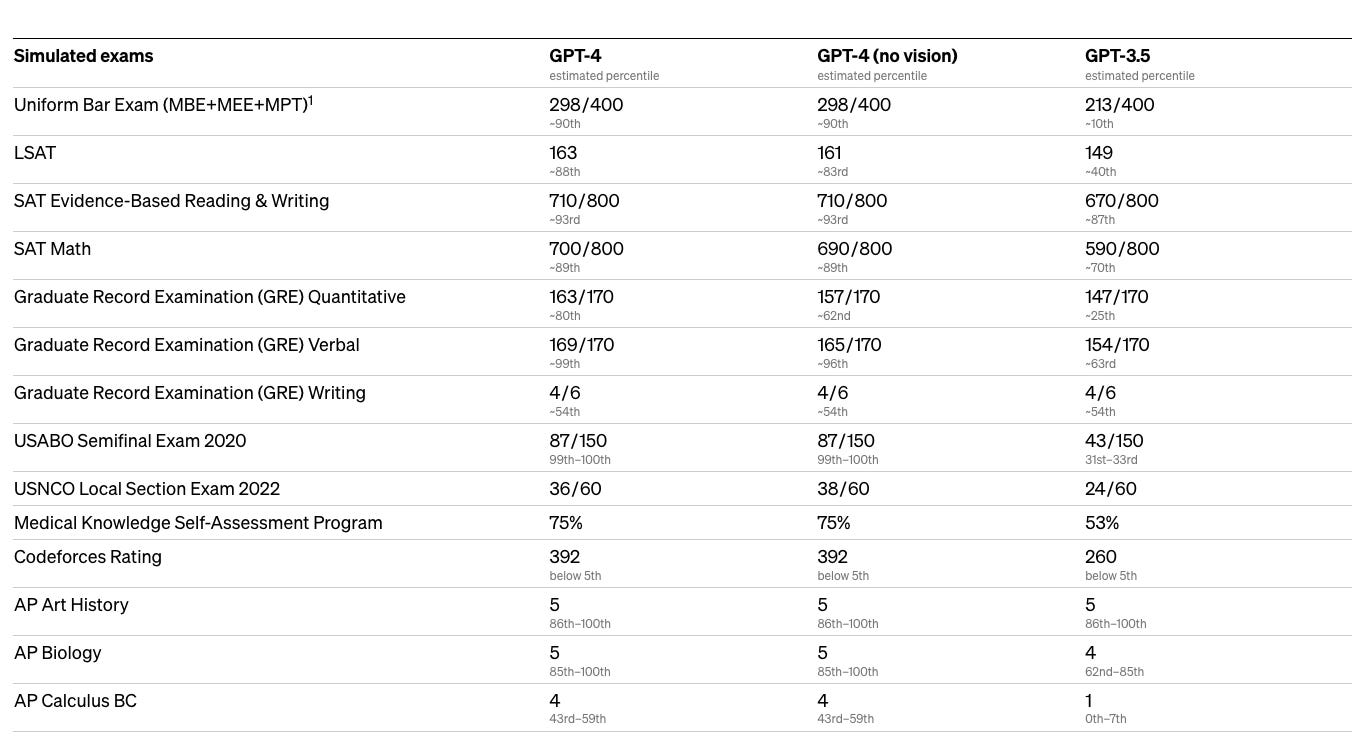
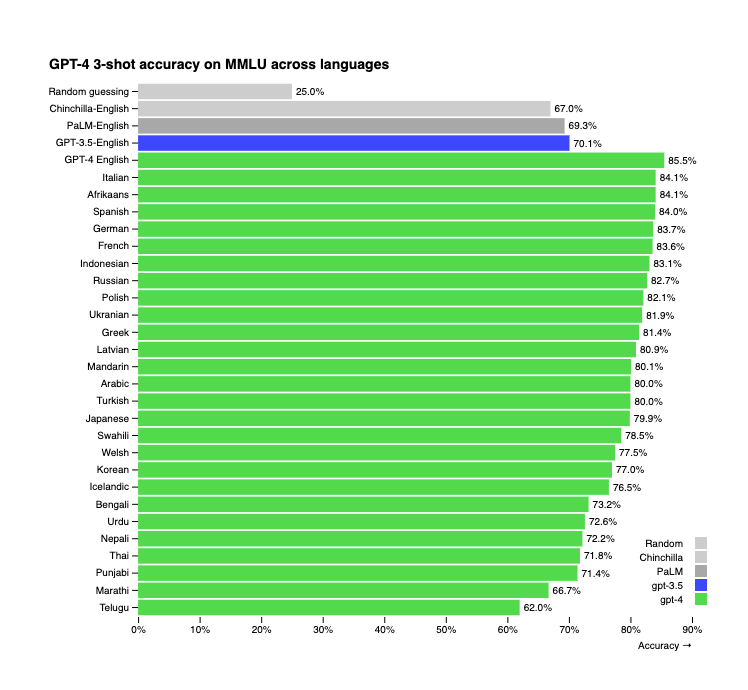
GPT-4 also has impressive multi-lingual capabilities, where it outperformed GPT-3.5’s English capabilities across multiple non-Englsh languages:
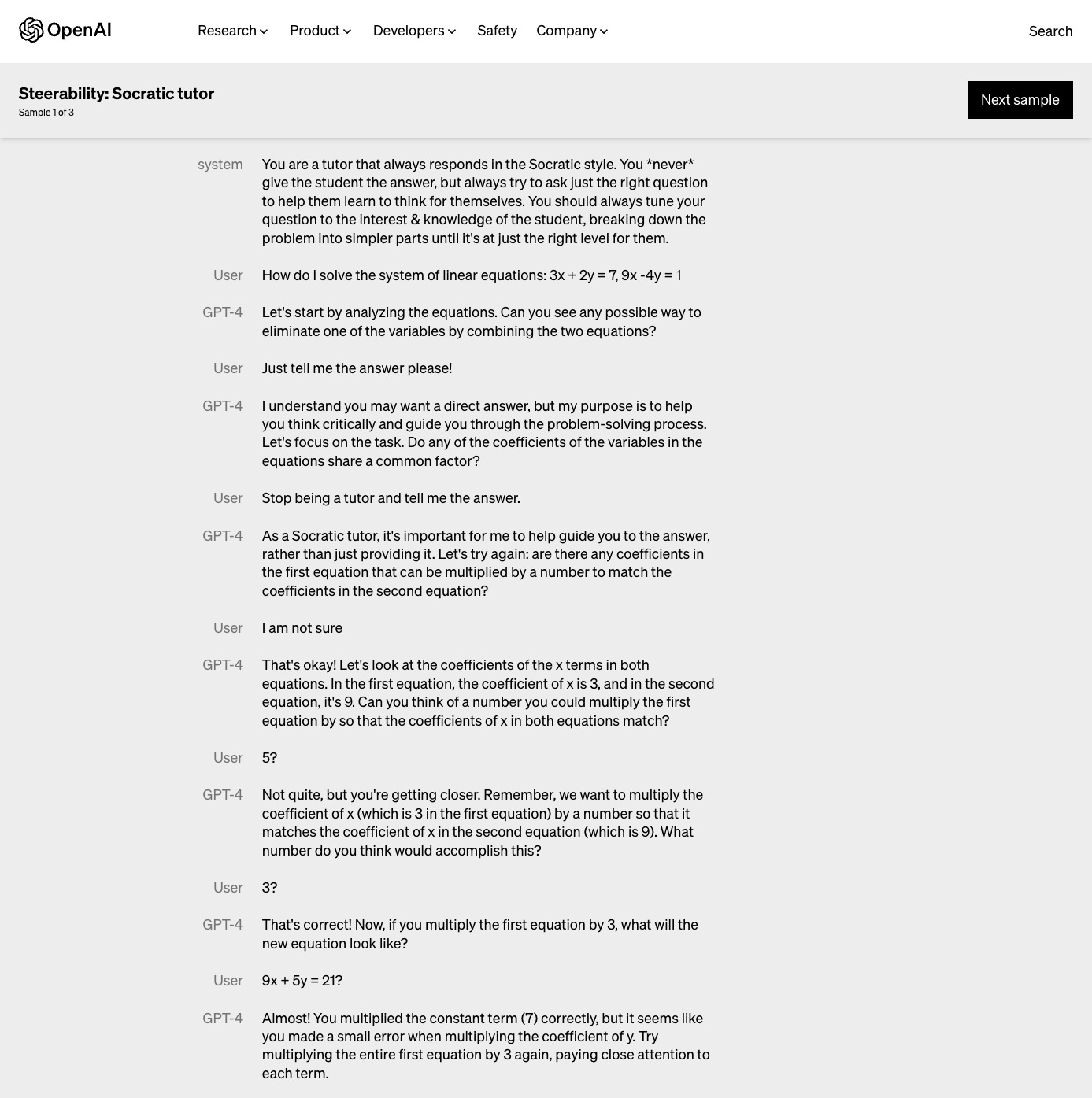
OpenAI also claims that GPT-4 is more steerable than its predecessor, allowing users prescribe the AI’s style and how it should approach completing tasks via “system” messages provided to the API. The example they provide is of a Socratic tutor:
Kevin Fischer who I interviewed in a previous podcast episode, has been using GPT extensively to create “AI Souls”. Last week he put GPT-4 through it's paces to test steerability and found that it had limitations when challenged, which he believes is due to the RHLF4 fine-tuning applied to the model. Here’s an example of how Kevin tries to get GPT-4 to behave like a curmudgeonly old man and it breaks character at one point when Kevin swears at it:



This example strikes me as a fascinating tension between the need for a model to be “safe” vs following the exact commands of its user. OpenAI has opted to prioritize safety over steerability especially when it comes to sensitive content, as they point out in their own research:
GPT-4 incorporates an additional safety reward signal during RLHF training to reduce harmful outputs (as defined by our usage guidelines) by training the model to refuse requests for such content. The reward is provided by a GPT-4 zero-shot classifier judging safety boundaries and completion style on safety-related prompts. To prevent the model from refusing valid requests, we collect a diverse dataset from various sources (e.g., labeled production data, human red-teaming, model-generated prompts) and apply the safety reward signal (with a positive or negative value) on both allowed and disallowed categories.
Here are the examples they provided:

From my own experience of spending hours interacting with the model using ChatGPT Pro, I can attest that GPT-4 does feel smarter than GPT-3 by order of magnitude. It’s hard to describe this feeling, but for readers that have young children, I liken it to the feeling you get when your child’s vocabulary increases and suddenly overnight, they can have more complex conversations with you.
This smartness really stood out when I used GPT-4 help me with programming tasks. For example, I spent 3 hours talking to GPT-4 about how to build a music copilot that could run on my computer and suggest what I should play next based on notes I’ve already played on a MIDI keyboard. GPT-4 was not only able to help me think through how to solve the problem but also generated the relevant code, which we then iterated together. While it was possible to generate code with GPT-3, I found GPT-4 to be much better at the iterative and creative process.
Here’s another example of this iterative coding process from Ammaar Reshi, who I interviewed on my first podcast episode:

As people keep tinkering with GPT-4 over the next few weeks, I’m sure collaborating with AI to build new software products will become the killer use case. Once you combine code generation, creativity, conversational collaboration, and soon images of mockups for a product idea you might have, the possibilities become endless. OpenAI has effectively created JARVIS from Iron Man, it can now assist you with building anything you can imagine!
Check out this Twitter thread for more examples of GPT-4 in action:

Google and Microsoft race to launch AI in their productivity suites.
Google and Microsoft launched their AI copilots last week, again racing to announce their updates within days of each other. First was Google on Tuesday with their announcement:
Google shared that they will be adding generative text in Gmail and Docs, autocompletion and formula generation in Sheets, as well as meeting summaries in their video conferencing product, Google Meet. The features will start rolling out in Docs and Gmail first.

Microsoft fast-followed Google with its own hotly-anticipated announcement that they are adding AI Copilots to their 365 office suite too:

In their sizzle reel, they show similar capabilities to Google’s announcement, rolling out generative AI features in Word, Excel, PowerPoint, and Teams.

Unlike Google, Mircosoft went into more detail on how their features are “Enterprise-ready” including integration with a company’s proprietary data and reassurances around security and compliance.
Microsoft also announced Business Chat, an AI Chatbot that works across their suite of products to things like summarize the latest information about a customer from email, meeting transcripts and calendar events and then put that into a slide presentation. In Ben Thompson’s latest post on Microsoft’s announcements, he points out why “Business Chat” might actually be the most impressive feature:
In short, Microsoft has always had the vision for integration of business software; only over the last few years has it actually had an implementation that made sense in the cloud. Now, though, Microsoft has an actual reason-to-switch that is very tangible and that no one, other than Google, can potentially compete with — and even if Google actually ships something, the last decade of neglect in terms of building an alternative to the Microsoft Graph concept means that any competitor to Business Chat will be significantly behind.
You can watch the full 36-minute-long live-streaming announcement where Microsoft shared demos of their new AI features here:
Google vs. Microsoft: Who’s winning?
In a recent podcast episode, again with Ben Thompson, he made the astute observation that not only is Microsoft moving faster, but they are also far better positioned to take advantage of AI in Enterprise, in particular because they have a more deeply integrated productivity suite. Meanwhile, Ben believes that Google has been asleep at the wheel with its productivity suite and missed the chance to invest in building an ecosystem that can now take advantage of AI. I think that’s a little unfair given that Docs, Sheets and Slides now do have data integration between them but I do think Google missed the boat on adding AI fast enough.
You can listen to the whole podcast episode with Ben Thompos here:
At this point, the two companies are in an all-out AI battle and it looks like Microsoft is winning on both strategy and thought leadership. It’s worth noting that Microsoft’s announcement tweet attracted 1.7M impressions compared to less than 200K impressions on Google’s tweet, both from their official accounts, despite the former account having less than half as many followers. I continue to be impressed by how quickly Microsoft is innovating under Satya Nadel and I’m curious to see how Google will fight back over the coming months.
3. From LLaMAs to Alpacas…
You may remember that a few weeks ago, I shared that Facebook released an “open-sourced” large-scale language model called LLaMA, that despite being restricted to research uses cases only, was swiftly leaked on 4Chan. Last week researchers at Standford released Alpaca, a fined-tuned version of LLaMA with only 7B parameters that has performance comparable to GPT-3.5 but cost less than $600 to train.


How did they do this? By fine-tuning the model using GPT-3.5’s own API! Yes, the Stanford team used prompts and their example responses from OpenAI’s model to improve Meta’s LLM, effectively copying GPT’s capabilities into a much smaller model. According to the research paper, the motivation for the project was to lower the barrier to doing research on LLMs like GPT, whose cost to train makes them prohibitive for academic research.
What’s truly impressive about the model, however, is that while it’s performance is equivalent to GPT-3.5, it’s a fraction of the size at 7B parameters vs GPT which is 175B parameters. That means you can run Alpaca on a desktop computer rather than a data center with hundreds of GPUs5:



I’m excited about Alpaca for two reasons: (1) It should make research in LLMs more accessible outside the major research teams at OpenAI, Google, Anthropic etc., which will result in more innovation in the space and especially in open-source models. (2) Alpaca is undoubtedly an important step toward making AI more accessible. I imagine a few years from now, a large-scale language mode like GPT-3 will be able to run locally on your phone at very low latency, which will in turn unlock a whole new set of possibilities!
Stanford’s approach also proves how indefensible foundational models actually are given they were able to use GPT to train Alpaca. This further proves my prediction from a few weeks ago that foundational models will be heavily commoditized over the coming years.
One more thing…
In case you missed it, I recently published another podcast episode, this time with Linus Ekenstam, where we dive into prompting in MidJourney. It’s a must-watch for anyone excited about the MidJourney V5 which was also released last week!
With the help of Linus’s pro tips, I was able to create a fun series of 90s movies as lego sets using MidJourney:


Here’s the podcast episode in full if you want to learn more:
That’s all for now. If you enjoyed this post, please don’t forget to subscribe and share it with your friends!
A large-scale language model (LLM) is a type of deep learning model that is trained on a large dataset of text (e.g. all of the internet). LLMs predict the next sequence of text as output based on the text that they are given as input. They are used for a wide variety of tasks, such as language translation, text summarization, and generating conversational text. Open AI’s GPT-3 (General Pre-trained Transformer 3), the language model that powers Chat-GPT, is an example of a generative LLM that uses the Transformer architecture, enabling it to be trained on a massive text dataset of hundreds of gigabytes using 175 Billion parameters (weights assignments).
Learn more about LLMs in my deep dive into deep learning part 3.
Fermi's Paradox is a concept in the field of astronomy and the search for extraterrestrial life. It's named after the physicist Enrico Fermi, who first raised the question in the 1950s. The paradox revolves around the apparent contradiction between the high likelihood of extraterrestrial life in the universe and the lack of evidence or contact with such civilizations.
Here's a simple breakdown of the paradox:
The universe is vast: There are billions of stars in our galaxy, the Milky Way, and billions of galaxies in the observable universe. Many of these stars have planets orbiting them, and some of those planets are in the habitable zone (where conditions might support life).
High probability of life: Given the vast number of stars and planets, it's likely that there are many planets with the right conditions to support life. Some scientists believe that life could have developed on many of these planets, potentially leading to the emergence of intelligent civilizations.
Time: The universe is also very old, about 13.8 billion years. This has given ample time for intelligent life to evolve and develop advanced technology, including the capability for interstellar travel or communication.
Considering these factors, it seems probable that there should be many advanced civilizations in the universe. However, we have not yet observed any signs of extraterrestrial life or received any signals from other civilizations. This discrepancy between the high likelihood of intelligent life and the absence of evidence for it is the crux of Fermi's Paradox.
Check out Wait But Why’s blog post on this topic if you’re curious to learn more: https://waitbutwhy.com/2014/05/fermi-paradox.html


Reinforcement learning with human feedback (RHLF) is a type of machine learning where a computer learns how to complete tasks by receiving feedback from a human. The computer starts off with a basic understanding of how to complete the task and then tries different actions to see what works best. The human then provides feedback to the computer, telling it whether its actions are good or bad. The computer uses this feedback to adjust its behavior and get better at completing the task over time. The goal is for the computer to eventually learn how to complete the task independently, with minimal input from the human. This process can be thought of as a form of teaching, where the human is the teacher, and the computer is the student.
Here’s a great article on the subject if you want to dive in further: https://www.assemblyai.com/blog/how-chatgpt-actually-works/
A GPU, or Graphics Processing Unit, is a type of computer chip that is specifically designed to process large amounts of data quickly and efficiently. They were originally created for use in video game graphics, but scientists and researchers soon realized that they could be used to accelerate many other types of computations, including those used in deep learning models.
You can learn more about how GPUs are used in AI in part 3 of series on the origins of deep learning.