

🤓A Deep Dive into Deep Learning: Part 3
🤓A Deep Dive into Deep Learning: Part 3
The last of 3 posts on the history of Deep Learning and the foundational developments that led to today’s AI innovations.
Hi Readers!
Thank you for subscribing to my newsletter. Here’s the final part of my deep dive into the origins of deep learning. In case you missed it, here are Part 1 and Part 2.
The field of deep learning is filled with lots of jargon. When you see the 🤓 emoji, that’s where I go a layer deeper into foundational concepts and try to decipher the jargon.
P.S. Don’t forget to hit subscribe if you want to receive more AI content like this!
Part 3 - The AI Spring
We ended Part 2 at the turn of the century with a small group of dedicated researchers pushing forward the field of neural networks, despite the skepticism of the wider academic community. Meanwhile, limitations in computing power at the time made it harder to train larger models to solve more complex problems.
So how did we get from the AI winter of the 70s, 80s, and 90s to the exponential advancements we’re experiencing today? Let’s pick things up in the 2000s, where we rejoin Geoffrey Hinton and his team…
2000s: Deep Learning Accelerates
In the 2000s, Hinton and his team continue to make major advancements in deep learning, building on the foundation laid in the 1990s. They develop new training algorithms that improve the effectiveness of deep learning models, particularly Deep Neural Networks (DNNs). Their most notable contributions include "pre-training" and "fine-tuning," which they first successfully use in creating Deep Belief Networks (DBNs) in 20061.
Hinton and his team propose a way to train neural networks by starting with simpler networks first and then building on top of them. This method, called "pre-training," helps the deeper networks learn more effectively. After pre-training, the team fine-tuned the network by adjusting it using a method called "supervised learning." This helped the network improve its performance even further. Deep Belief Networks were one of the first successful examples of deep learning architectures that used pre-training, fine-tuning and unsupervised learning.
🤓 What is a Deep Belief Network?
Deep Belief Networks (DBNs) are a type of neural network trained using a special technique called unsupervised learning. This means the network is not given specific answers or expected outputs to learn from. Instead, the goal of a DBN is to find patterns and structures in the data on its own.
One example of how this works is in image recognition. Imagine we have a dataset of images of handwritten digits, and we want to train a DBN to recognize these digits. The visible layer of the DBN would represent the pixels of the images, and the hidden units would be used to identify the underlying structure of the images. For example, the hidden units might learn to recognize edges, corners, and other simple shapes in the images. These simple shapes can then be combined to form more complex shapes such as digits.
However, DBNs are different from both Deep Neutral Networks (DNNs) and Convolutional Neural Networks (CNNs) covered in Part 2. DNNs use hidden layers to extract abstract and higher-level features from the input data, while CNNs use filters to identify specific features in images. DBNs, on the other hand, are unsupervised and learn the actual structure of the image that can later be combined to generate new images.
A key component of DBNs is the use of Restricted Boltzmann Machines (RBMs). RBMs are a type of neural network made up of two layers: a visible layer and a hidden layer. The visible layer represents the input data and the hidden layer is used to learn a compressed representation of the input data. RBMs are probabilistic generative models, meaning they can learn the probability distribution of the input data and generate new samples that are similar to the training data.
In a DBN, multiple RBMs are stacked on top of one another. Each RBM learns a more abstract and higher-level representation of the data as it progresses through the network. This is similar to how a puzzle has many pieces that need to be put together to form a complete picture. The idea is that by stacking multiple RBMs, the DBN can learn a more detailed and accurate representation of the input data.
Once the DBN has been pre-trained using these stacked RBMs, it can then be fine-tuned using a labeled dataset and supervised learning techniques, such as backpropagation, to improve its performance on a specific task. This is similar to how a detective would use clues from a crime scene to make an arrest.
Overall, Deep Believe Networks have been used in a variety of applications, such as image and speech recognition, and have played a significant role in the advancement of deep learning.
2000s continued: Off to the races!

As the decade proceeds, advancements in deep neural networks and the availability of large-scale datasets like Fei-Fei Li’s ImageNet2 and pre-trained models makes deep learning much more approachable. Researchers no longer need expensive and time-consuming data collection and annotation to train effective deep learning models. This leads to an era of competitive research, with teams from around the world seeing who trains the most accurate models.
One of these competitions is the Netflix Prize. The aim of the competition is to use machine learning to beat Netflix's own recommendation software's accuracy in predicting a user's rating for a film given their ratings for previous films by at least 10%. The prize is won in 2009 by BellKor's Pragmatic Chaos, a team whose members include employees of AT&T and Yahoo.
At the same time, another development comes along that literally accelerates the field of deep learning: The use of Graphics Processing Units (GPUs) in deep learning makes it possible to train large neural networks much more quickly than when using traditional processors on a computer.
🤓 Why do GPUs accelerate deep learning?
A GPU, or Graphics Processing Unit, is a type of computer chip that is specifically designed to process large amounts of data quickly and efficiently. They were originally created for use in video game graphics, but scientists and researchers soon realized that they could be used to accelerate many other types of computations, including those used in deep learning models.
Deep learning models, such as neural networks, typically involve a lot of complex mathematical calculations and require a lot of data to be processed at the same time. Training these models can take a long time on a regular computer, even with a fast processor.
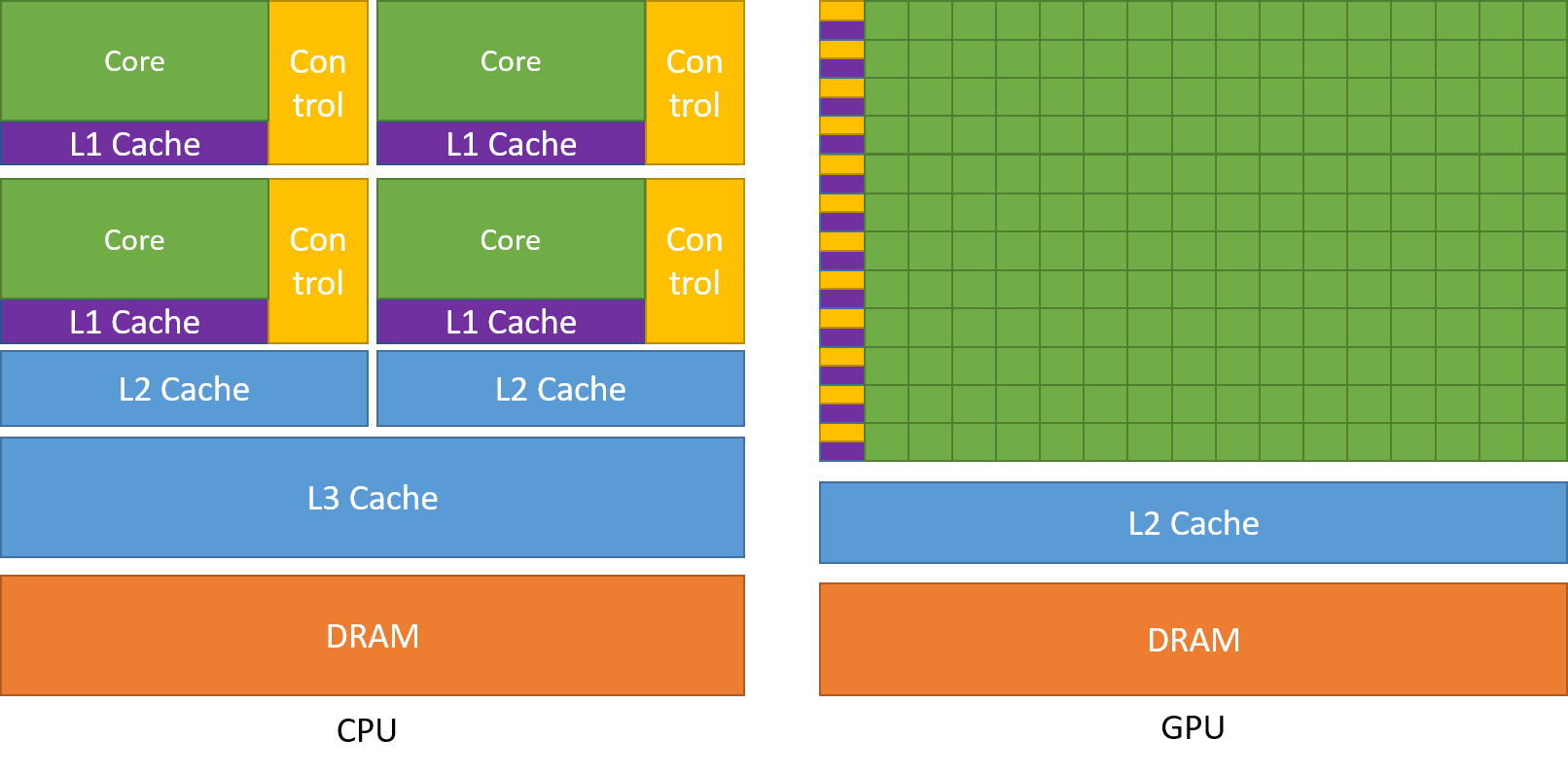
A CPU (Central Processing Unit) is divided into multiple cores so that they can take on multiple different tasks at the same time (e.g., browsing the internet while listening to Spotify). A GPU, on the other hand has hundreds and thousands of cores, which are dedicated to completing simple computations that are performed more frequently and independently of each other i.e. in parallel.
Training neural networks is an ideal task for GPUs. Calculating weights and activation functions of each layer and backpropagation can all be computed in parallel. A GPU is designed to handle these types of calculations much more efficiently. It can perform many calculations in parallel, which means it can work on many pieces of data at the same time. This allows deep learning models to be trained much faster on a GPU than on a regular computer.
As deep learning has progressed, it needs to have vast amounts of data to be fed and training on these data set takes a long time on a single CPU. With a single GPU, the time to train these models is significantly reduced, and with multiple GPUs working together in parallel, it's even faster.
2010s: “Hey Google…”

Thanks to the progress of the previous decade, the 2010s see exponential advancement in deep learning, with Apple, Google and Amazon all making major investments in the space ushering in the dawn of consumer-friendly AI. From automatically organizing your photos to helping you turn on the lights in your home and playing your favorite songs at the command of your voice, AI enters the mainstream and consumers lives.
The decade began with a seminal paper in 2012 by Geoffrey Hinton, Alex Krizhevsky and Ilya Sutskever that showed a massive leap in the accuracy of image recognition using deep neural networks3. Hinton and his colleagues developed AlexNet, a convolutional neural network that won several competitions.
In 2013 the film “Her” is released. A science fiction drama starring Scarlett Johansson as Samantha, an AI operating system who its user Theodore falls in love with. Samantha is portrayed as a highly intelligent and empathetic AI that is able to form a deep connection with Theodore. The film provides a very tangible sense of what the near future might look like with AI as part of our lives. At the same time, it also highlights the limitations of “AI Assistants” like Google Home, Siri, and Echo, which are far more limited in their ability.
🤓 How do voice assistants like Google Home, Siri and Echo work?
Remember from Part 2 how recurrent neural networks (RNNs) with long short-term memory are able to process longer sequences of input? That’s perfect for the use case of speech recognition in voice assistants, where a user makes a request with multiple words in a sequence.
Here’s a reminder of how RNNs work from Part 2:
An RNN might take a sequence of words as input and use the output from processing the previous word to inform its processing of the current word. This allows the RNN to capture the context and dependencies between words, which is important for understanding the meaning of the text.
RNNs work by using a feedback loop, where the output of a previous step is fed back into the network as input for the next step. This allows the network to "remember" what it has heard in the past and use that information to better understand the current input.
And here’s how LSTMs work, also from Part 2:
A long short-term memory (LSTM) unit is a type of recurrent neural network that is able to capture long-term dependencies in time series data. It is called "long short-term memory" because it is able to remember information for long periods of time and use it to make predictions or decisions later. For example, storing a whole sentence in a text to predict the next word vs just storing the last word.
LSTMs are a type of RNN that are particularly well-suited for handling speech data. They use a special structure called a memory cell, which can retain information for long periods of time and selectively choose which information to discard and which to keep. This allows LSTMs to effectively filter out irrelevant information, such as background noise, and focus on the important parts of the speech input, which is critical in the use case of Voice Assistants.
Together, RNNs and LSTMs form the backbone of AI voice assistants, allowing them to understand and respond to human speech in real-time. As more data is fed into these networks, they continue to learn and improve, making them even better at understanding and responding to human speech.
It is worth mentioning that, these models are trained on a massive amount of data, this allows them to generalize well and adapt to different accents, dialects, and speaking styles. It also allows them to understand and respond to new words and phrases, as well as recognize and respond to specific speakers.
But voice assistants aren’t just tasked with recognizing speech. They also respond to a user’s commands by synthesizing human-like speech too. For example, if you ask Google Home, “What’s the weather like today?” It will respond with an answer describing the current weather conditions and forecast for the rest of the day. This is where deep neural networks (DNNs) and convolutional neural networks (CNNs) come into play.
Here’s a reminder of how convolutional neural networks work from Part 2:
A CNN consists of multiple layers of interconnected neurons, which process and analyze the input data. The layers of a CNN are organized in such a way that they learn increasingly complex features of the input data as the data passes through the network.
One key feature of CNNs is the use of "convolutional" layers, which are designed to automatically learn and extract features from the input data. These layers apply a set of filters to the input data and use the resulting output to detect patterns or features in the data. This process is repeated multiple times, allowing the CNN to learn increasingly complex features of the input data as it passes through the network.
In speech synthesis, DNNs and CNNs are used to model the complex relationships between audio signals and human speech. These models are trained on large amounts of speech data, and they learn to recognize patterns in the data that are associated with different speech sounds, such as phonemes and words. They are then used to generate new speech from text by predicting the most likely sequence of speech sounds for a given input text.
DNNs and CNNs are powerful tools for speech synthesis, as they can learn to model the complex relationships between audio signals and human speech, and generate new speech from text with high accuracy. They are the foundation of most of the AI voice assistants like Siri and Google home.
It’s worth noting however, that voice assistants are limited in their ability because they are based on a set of predefined rules and commands. They are not truly intelligent because they do not have the ability to learn and adapt like a human would. They rely on a set of programmed responses and cannot understand context or make decisions based on new information.
2010s continued: The race to general intelligence begins
In the 2010s, startups like OpenAI and Deepmind (acquired by Google in 2015 for over $400M) are funded with the explicit goal of achieving Artificial General Intelligence (AGI). AGI is a type of artificial intelligence designed to possess a broad range of cognitive abilities similar to those of a human being. This includes the ability to understand complex concepts, reason, plan, solve problems, and learn from experience similar to our idea of AI from sci-fi movies like “Her”. This new injection of capital into AI research from startups and big tech companies spurs an exponential increase in advancements in the field.
One of these new developments is generative models. These are models that are designed to generate new output data rather than classify or recognize input data. One of the most popular early generative models is the Generative Adversarial Network (GAN) which was introduced by Ian Goodfellow in 20144. The main advantage of GANs is the ability to generate new data that is similar to the training data, allowing them to be used for tasks such as image synthesis, image-to-image translation, and other generative tasks.
🤓 What is a Generative Adversarial Network (GAN)?

Generative Adversarial Networks (GANs) are a class of generative models that use a technique called adversarial training, where two neural networks, a generator, and a discriminator, are trained together.
The generator network learns to generate new data samples that are similar to the training data. It takes in a random noise as input, and it produces a new data sample that is similar to the training data. The generator is typically a neural network with an architecture designed to produce new data samples, such as a decoder network.
The discriminator network, on the other hand, takes in both real data samples from the training set and fake data samples generated by the generator. It is trained to distinguish between the real data samples and the fake data samples generated by the generator. The discriminator is also typically a neural network but with an architecture designed to distinguish between real and fake data samples.
The training process of a GAN is an adversarial process where the generator and discriminator are trained simultaneously and in opposition. The generator is trained to produce data samples that can fool the discriminator into thinking they are real, while the discriminator is trained to correctly identify the real data samples from the fake ones generated by the generator.
At the beginning of the training, the generator produces poor-quality samples, the discriminator easily recognizes them as fake, and thus the generator is updated to improve its performance. As the training progresses, the generator improves and generates better-quality samples, making it harder for the discriminator to distinguish between real and fake data. The discriminator also improves by training on both real and fake samples. The training continues until the generator can produce samples that can fool the discriminator.
This process is called adversarial training; the generator and discriminator are competing with each other, and the generator is trying to produce realistic samples that the discriminator would not be able to tell apart from the real ones. This leads to the generator learning to produce samples that are similar to real ones.
2010s continued: Transformers - More than meets the eye?

Arguably one of the most revolutionary breakthrough in deep learning in the 2010s is the invention of the Transformer architecture in 2017 by Google researchers in the famously titled paper “Attention is All You Need”5. In the paper, Google’s researchers propose “a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.”
The advent of the Transformer architecture has played a significant role in the development of large-scale language models (LLMs) such as OpenAI’s GPT-3, which powers ChatGTP. These Large-scale language models are essentially transformer-based architectures that are trained on large amounts of text data, and have billions of parameters, which allows them to understand the input more effectively, generate more coherent and human-like text, and generalize better on unseen examples.
Before the transformer architecture, Recurrent Neural Networks (RNNs) were the most commonly used architecture for language modeling tasks. However, RNNs are not well-suited for processing long sequences of text and have difficulty learning long-term dependencies in the input.
🤓 What is the Transformer architecture?
Remember from earlier that recurrent neural networks and convolutional neural networks store a fixed length part of their input in memory in hidden layers so that they can better predict the output. The challenge with this approach is that it requires the model to serially process its input, for example, processing a paragraph of text one word at a time. This process cannot be parallelized when training which creates challenges due to limitations in memory. It also limits how far back a model can learn about the text it is trained on for any word in the text, referred to as “lookback.”
The transformer architecture is based on the idea of allowing the model to look at the whole sequence of input rather than a fixed-length part of the input, like recurrent neural networks with long short-term memory do. Then the model focuses on certain parts of that input that are relevant to each word. It achieves this through a mechanism called self-attention, which you can liken to being able to look up different words in a dictionary.
Attention was first introduced in 2015 in the context of language translation from English to French. In the paper, the authors gave the example of translating the following English sentence
“The agreement on the European Economic Area was signed in August 1992.”
Into the French equivalent
“L’accord sur la zone économique européenne a été signé en août 1992.”
Trying to translate this sentence by going through each English word one by one wouldn’t work for many reasons: some French words are flipped, and the French language has gendered words.
Attention is a mechanism that allows the model to focus on every single word in the French input when generating the English output and pay more attention to specific words.

The model learns which words it should “attend” to from training data by processing thousands of French and English sentences.
Self-attention, unlike regular attention, doesn’t look at the attention of specific words for a given input and output, as this is limited to translations. Instead, it looks at the attention to give different words in the input for each word in the input itself. In order words, self-attention allows a neural network to understand a word in the context of words around it. This is important in NLP tasks such as language understanding, where the meaning of a word depends on the context and its relationship with other words in the sentence.
The transformer architecture also introduced the concept of multi-head attention, which enables the model to attend to multiple parts of the input simultaneously, which improves the performance of the model by allowing parallelization.
Additionally, the transformer architecture introduced the concept of position encoding, which allows the model to understand the order of the tokens in the input and make use of their relative position to better understand the meaning of the input.
Present Day: Hype builds around Generative AI
The Transformers architecture proves to be much better at handling large amounts of data and parallel processing than previous neural networks. This enables efficient training of deep, large models on GPUs, unlocking the exponential progress toward AI. Today, transformers enable the training of large-scale language models like GPT-3 that powers ChatGPT, a breakthrough product in AI, which I covered in my post, AI: Don’t believe the hype?:
Unlike it’s predecessors (e.g. Google Assistant, Echo, Siri), ChatGPT is really the first time an AI assistant truly seems like it could pass the Turing Test. There have been many impressive examples of ChatGPT in action and if you haven’t tried it yourself you should. ChatGPT successfully wrote a blog post for me and turned it into a twitter thread, gave me a recipe for pancakes that tasted delicious and helped me pick a Christmas present for my wife! What truly impressed me though is ChatGPT’s ability to be “creative”.
Today, the race is on between Google, OpenAI, and many other startups to build larger, more intelligent LLMs that may one day reach the holy grail of general intelligence.
🤓 How do large-scale language models like GTP-3 work?
A large-scale language model (LLM) is a type of deep learning model that is trained on a large dataset of text (e.g. all of the internet). LLMs predict the next sequence of text as output based on the text that they are given as input. They are used for a wide variety of tasks, such as language translation, text summarization, and generating conversational text. Open AI’s GPT-3 (General Pre-trained Transformer 3)6, the language model that powers Chat-GPT, is an example of a generative LLM that uses the Transformer architecture, enabling it to be trained on a massive text dataset of hundreds of gigabytes using 175 Billion parameters (weights assignments).
GPT-3’s size made it the largest language model at the time of its launch though it was later superseded by Google’s PaLM which boasts over 540 billion parameters. GPT-3s use of the Transformer architecture allows it ot understand and generate language in a way previous models could not. It also made use of unsupervised learning, to be trained without any specific task in mind. This allows it to be fine-tuned for a variety of different tasks, such as text completion, question answering, and language translation.
Once LLMs get to this size, they start exhibiting emergent behavior, unexpected and seemingly autonomous actions or decisions that the model makes as a result of its training on the vast amount of data it has been exposed to. This can be seen in GPT-3's ability to generate human-like text that is often difficult to distinguish from text written by a human. However, it is important to note that this behavior is not truly autonomous, as it is still determined by the patterns and connections present in the training data.
Additionally, GPT-3's may generate text that appears to have a bias or hold certain beliefs, which is a reflection of the biases and beliefs present in the training data, highlighting the need for diverse and unbiased data when training such models. These large models are also prone to “hallucinations”, the term in AI for when a model makes up an answer in a way that appears to be factual but is not. For example, it may generate a citation to an academic paper that looks real but has the incorrect authors!
Final thoughts
It wasn’t until I wrote this series that I understood how much we should be grateful for the tireless efforts of a few researchers who laid the foundations for the astonishing progress we are seeing in deep learning today. Even a decade ago, there was still skepticism about the effectiveness of neural networks, which wasn’t really overcome until companies like Google invested hundreds of millions of dollars into the field. Now we’re on the verge of having self-driving cars, AI chatbots can pass the bar exam, and anyone can create art by just describing it! And the best part?
We're just getting started!

Feedback
Hi Readers!
I really enjoyed writing this series on deep learning and learned a lot myself while doing it. I would love to know if you found this series valuable in learning about AI?
Thanks for your feedback!
~AJ
P.S. If you did find this series valuable, do me a favor and share it with your friends interested in AI!
Fun fact: I used ChatGPT for a lot of the research for this series of posts. Over the course of a week I asked ChatGPT dozens of questions about the history of deep learning and the concepts behind it. To make sure the article was accurate, I asked ChatGPT to provide citations to relevant scientific papers which I’ve included in the footnotes. If you find any errors, please reach out or comment below and I will fix them!
Hinton, G. E., Osindero, S., & Teh, Y. W. (2006). A fast learning algorithm for deep belief nets. Neural computation, 18(7), 1527-1554.
In 2009, Fei-Fei Li, an AI professor at Stanford launched ImageNet, assembled a free database of more than 14 million labeled images. The Internet is, and was, full of unlabeled images. Labeled images were needed to “train” neural nets. Professor Li said, “Our vision was that big data would change the way machine learning works. Data drives learning.”
"ImageNet Classification with Deep Convolutional Neural Networks" was published in 2012 by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton.
"Generative Adversarial Networks" (Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680).
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 5998-6008
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.